Build and Run Agentic AI with NVIDIA Nemotron 3 Super on Bitdeer AI Model Studio

Bitdeer AI Model Studio now supports NVIDIA-Nemotron-3-Super-120B-A12B, bringing a new open model for advanced reasoning, long-context understanding, and agentic AI development to the platform.
Designed for complex multi-agent applications, Nemotron 3 Super combines strong reasoning accuracy with high compute efficiency. Developers can now explore and run this model on Bitdeer AI’s high performance NVIDIA GPU infrastructure, making it easier to experiment, deploy, and scale demanding AI workloads.
What is NVIDIA Nemotron 3 Super
NVIDIA Nemotron 3 Super, part of the Nemotron 3 family of open models, is optimized for complex multi-agent applications. NVIDIA-Nemotron-3-Super-120B-A12B is a 120B-parameter model built on a hybrid Mamba-Transformer Mixture-of-Experts (MoE) architecture, activating only 12B parameters during inference. This design delivers strong performance on complex reasoning tasks while remaining efficient enough for production-scale deployment.
What makes this model particularly notable is its focus on agentic workloads. Rather than being optimized only for general chat, Nemotron 3 Super is built for scenarios where models need to reason across long contexts, call tools accurately, and support multi-step task execution.
Key Specifications:
- Model Size: 120B total parameters with 12B active parameters during inference.
- Architecture: Hybrid Mamba-2 + SSM + Transformer with Mixture-of-Experts (MoE) routing.
- Context Length: Supports up to 1M tokens for long-context reasoning.
- Accuracy: Leading accuracy on the Artificial Analysis Intelligence Index within its model size category.
- Minimum GPU Requirement: 2× H100-80GB
- Multilingual Support: English, French, German, Italian, Japanese, Spanish, Chinese
Key architecture innovations
Agentic AI systems require models capable of advanced reasoning, coding, and long-context analysis, while remaining efficient enough to operate continuously at production scale.
However, multi-agent workflows introduce additional complexity. Compared with traditional chat interactions, these systems generate significantly more tokens as agents repeatedly exchange conversation history, tool outputs, and intermediate reasoning steps across multiple turns. Over long tasks, this expanded context can increase inference costs and introduce challenges such as communication overhead and context drift.
To address these requirements, Nemotron 3 Super is built around several key architectural design principles.
- First, the hybrid Mamba-Transformer architecture improves the model’s ability to process long sequences efficiently while retaining the reasoning strengths of transformer layers.
- Second, the Mixture-of-Experts routing mechanism dynamically selects specialized expert networks for each task, enabling higher performance without proportionally increasing inference cost.
- Third, the model is designed as a fully open model stack, including open weights, training datasets, and training recipes. This allows developers to customize and fine-tune the model on their own infrastructure while maintaining control over data privacy and security.

A layer pattern diagram showing repeating blocks of Mamba-2/MoE pairs interleaved with attention layers
Source: NVIDIA
Together, these capabilities make Nemotron 3 Super particularly well suited for building complex multi-agent systems and enterprise AI workflows. And Nemotron 3 Super is optimized for tool calling, multi-step reasoning, and agent orchestration. These capabilities are essential for emerging AI agent systems, where models must interact with external tools, APIs, and data sources to complete tasks.
Benchmark performance
Nemotron 3 Super delivers leading accuracy across several agentic and reasoning benchmarks while maintaining high throughput efficiency. The model demonstrates strong capabilities in instruction following, coding, tool use, and long-context reasoning.
The benchmark results below highlight its performance across key agentic evaluation tasks.
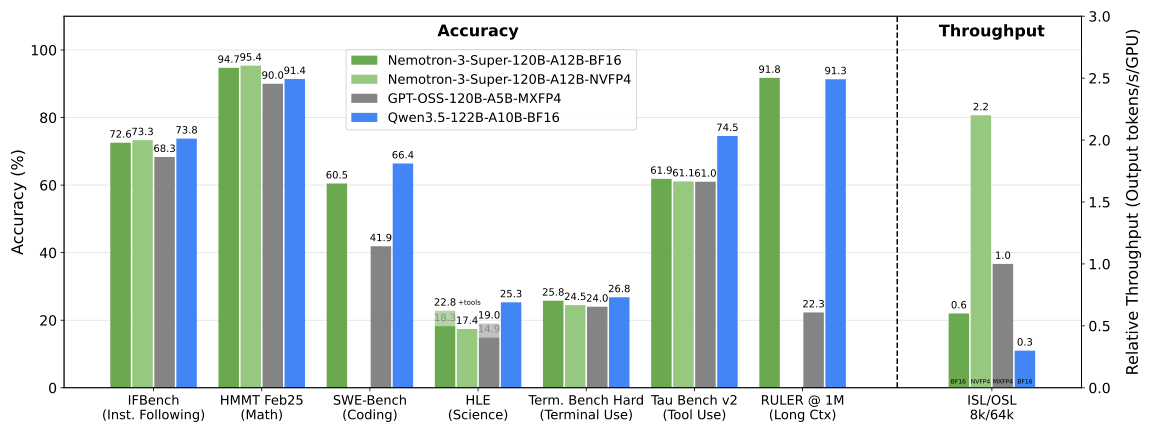
A chart comparing Nemotron 3 Super accuracy on key benchmarks against similarly sized open models.
Source: NVIDIA
Enterprise use cases
Nemotron 3 Super is designed for complex enterprise AI applications, particularly those that involve multi-agent reasoning and large knowledge contexts. These capabilities make the model well suited for a variety of industry use cases where advanced reasoning and scalable AI workflows are required. Below are several representative examples:
Software Development:
With strong coding and tool-calling capabilities, as well as the ability to work across large codebases, Nemotron 3 Super can support end-to-end software development workflows, including code generation, automated debugging, and testing.
Deep Research and Search:
Nemotron 3 Super has demonstrated strong performance in enterprise research workflows, with capabilities well suited for comprehensive report generation and precise factual recall. This makes it a strong fit for literature review, competitive intelligence, and research automation.
Cybersecurity: High-accuracy tool calling enables autonomous agents to select the appropriate tools more reliably, reducing execution errors in high-stakes environments such as security operations and automated cybersecurity workflows.
Financial Services:
Nemotron 3 Super can process large volumes of financial reports and long-context documents in a single workflow, helping analyst agents maintain context over extended tasks and improving both efficiency and analytical accuracy.
Run Nemotron 3 Super via API on Bitdeer AI Model Studio
Bitdeer AI Model Studio is a serverless inference platform where you can immediately access and run foundation models like Nemotron 3 Super through a simple API.
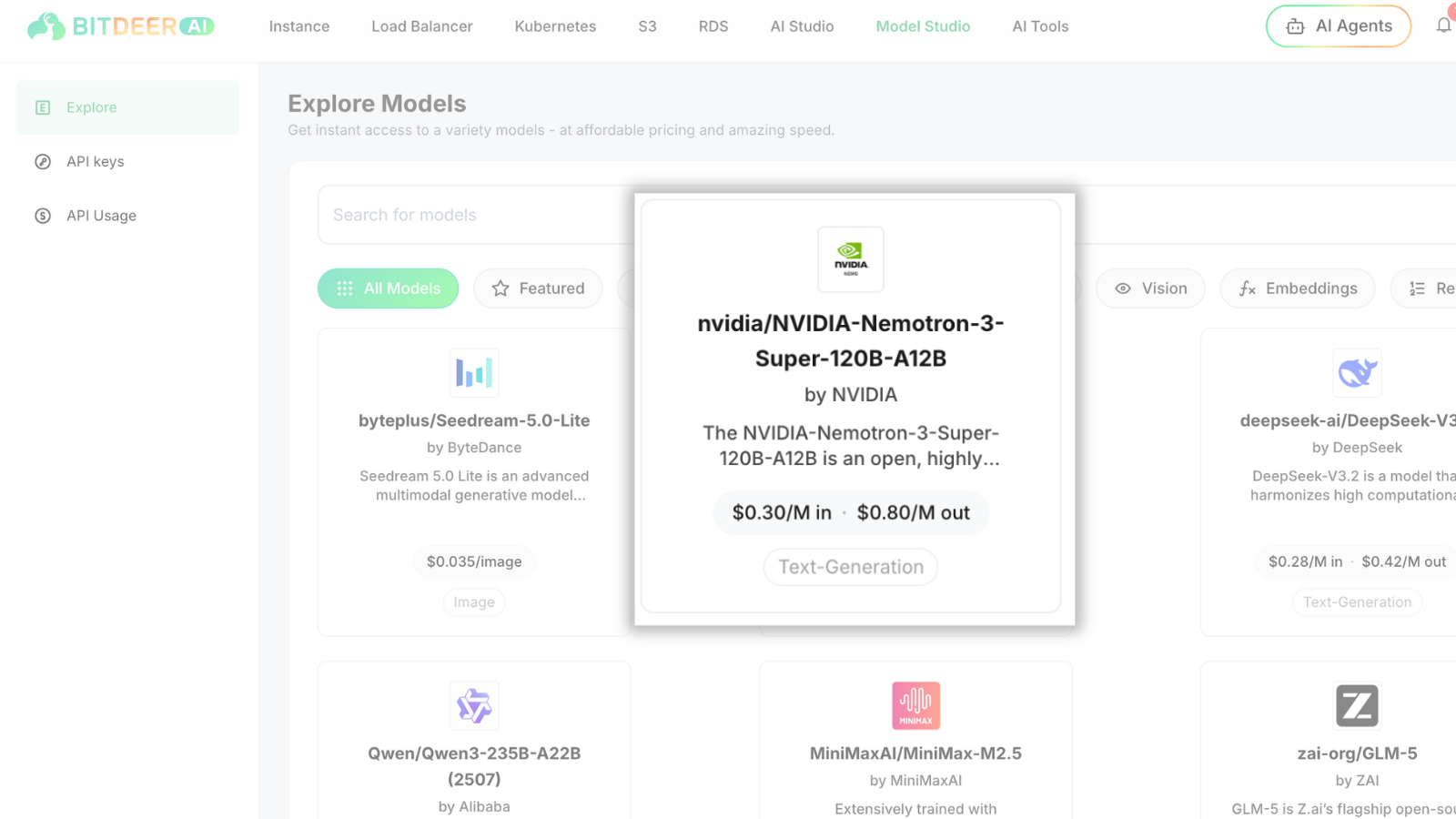
Step 1: Select the Model
Log in to Bitdeer AI Model Studio , locate NVIDIA-Nemotron-3-Super-120B-A12B in the model list, and start using it for your AI workloads, priced at $0.30/M in ·$0.80/M out.
Step 2: Generate an API Key
Before using the model, you need an API key. Go to API Keys in the left navigation panel and click Generate API Key.
Step 3: Call the Model via API
Once the API key is created, you can call the model using the Bitdeer AI inference API by including your API key in the request header.
With Model Studio and API access, developers can quickly start experimenting with Nemotron 3 Super and integrate the model into their AI applications.
Conclusion
With strong reasoning capabilities, long-context support, and an efficient hybrid architecture, NVIDIA-Nemotron-3-Super-120B-A12B provides a powerful foundation for building advanced AI applications. From complex reasoning and coding tasks to large-scale knowledge processing and agentic workflows, the model enables developers to tackle demanding workloads with greater efficiency and flexibility.
Ready to experience NVIDIA-Nemotron-3-Super-120B-A12B in action? Explore the model on Bitdeer AI Model Studio and see how it can accelerate your next AI applications.