Stateful LLMs and AI Agents with Long‑Term Memory

The earliest chatbot models were goldfish: every new prompt wiped their memory clean; 2025 is the year they finally start acting more like elephants. By fusing large‑context language models with external memory stores, developers can now build stateful agents that remember users, projects and decisions for days, or even across entire product lifecycles. The limitation of short term memory is disappearing, thanks to two converging trends:
- Long‑context language models: open‑source projects such as Qwen 2.5‑1M (1 M‑token window) and Gradient AI's Llama‑3 Gradient (256 k → 1 M tokens) bring “elephant‑like” recall to self‑hosted stacks.
- Memory‑aware frameworks: LangChain, Llama‑Index, and Haystack make it straightforward to pair those models with vector stores, knowledge graphs, and episodic‑summary loops.
Even proprietary models are adapting quickly: OpenAI’s new GPT‑4.1 also sports a million‑token window, proving that giant context size is becoming a baseline feature rather than an exotic add‑on.
Why Stateful AI Matters
Traditional LLMs are like brilliant conversationalists with amnesia. Each interaction starts fresh, with no recollection of prior exchanges unless context is explicitly fed in. This stateless approach works for simple queries but falls short in scenarios requiring continuity, like a virtual assistant that learns your preferences, a customer service agent that recalls past issues, or an AI analyst that tracks evolving trends.
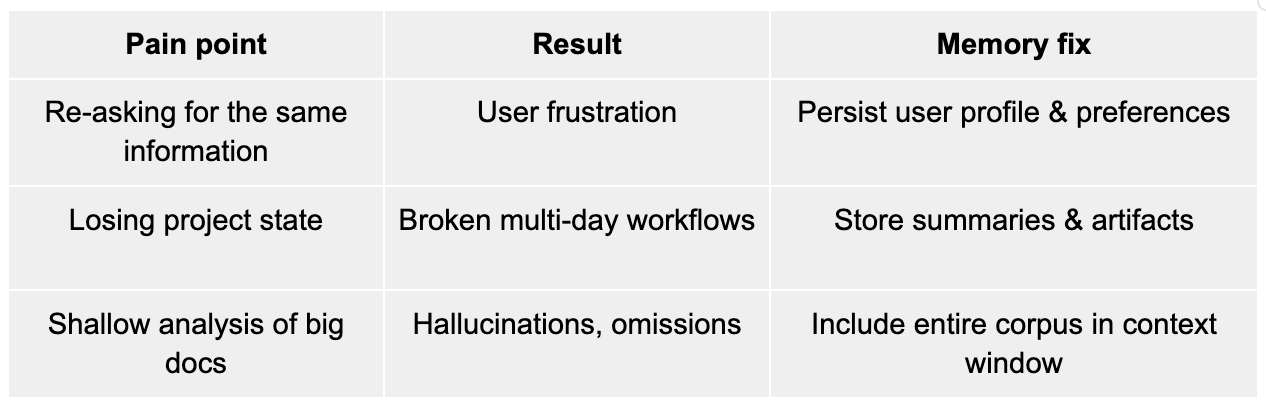
Stateful LLMs and AI agents solve this by maintaining long-term memory, enabling them to:
- Personalize at Scale: Remember user preferences, history, and context to deliver tailored responses.
- Reason Over Time: Build on past interactions to make informed decisions or predictions.
- Automate Complex Workflows: Handle multi-step tasks, like project management or supply chain optimization, with continuity.
Building stateful AI is no trivial feat. It demands robust architectures to manage memory, ensure scalability, and avoid performance bottlenecks. Here’s how it’s done:
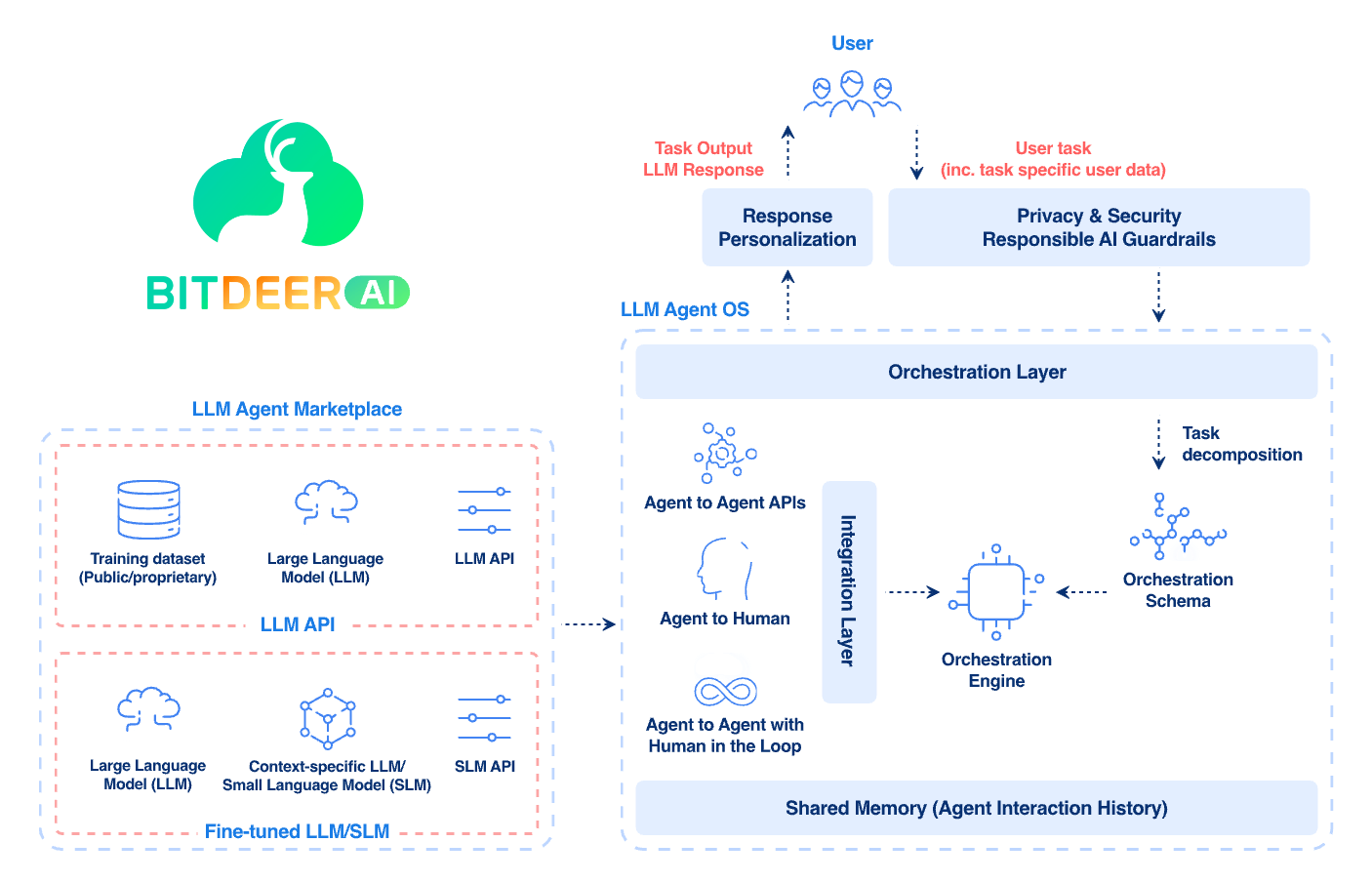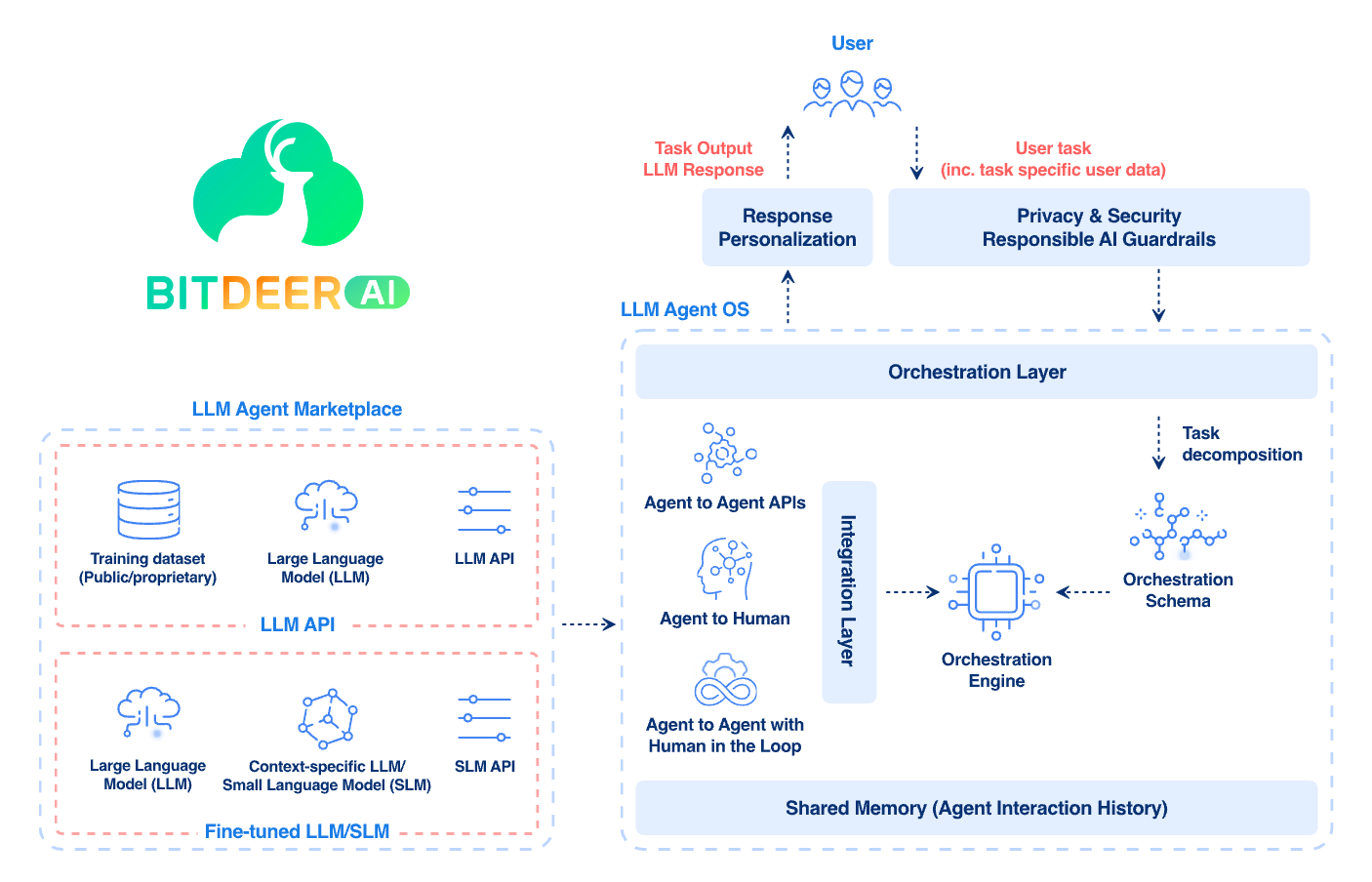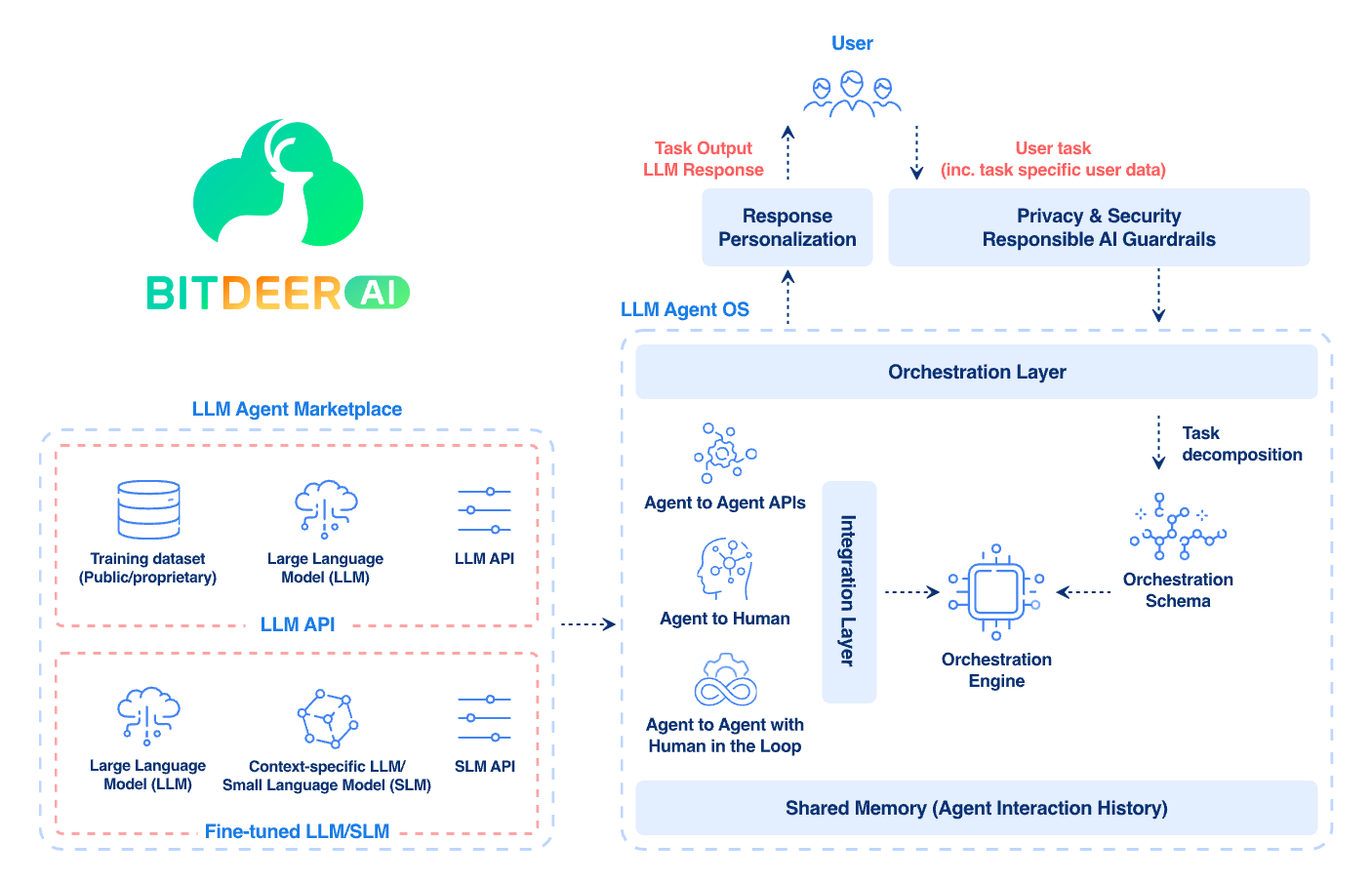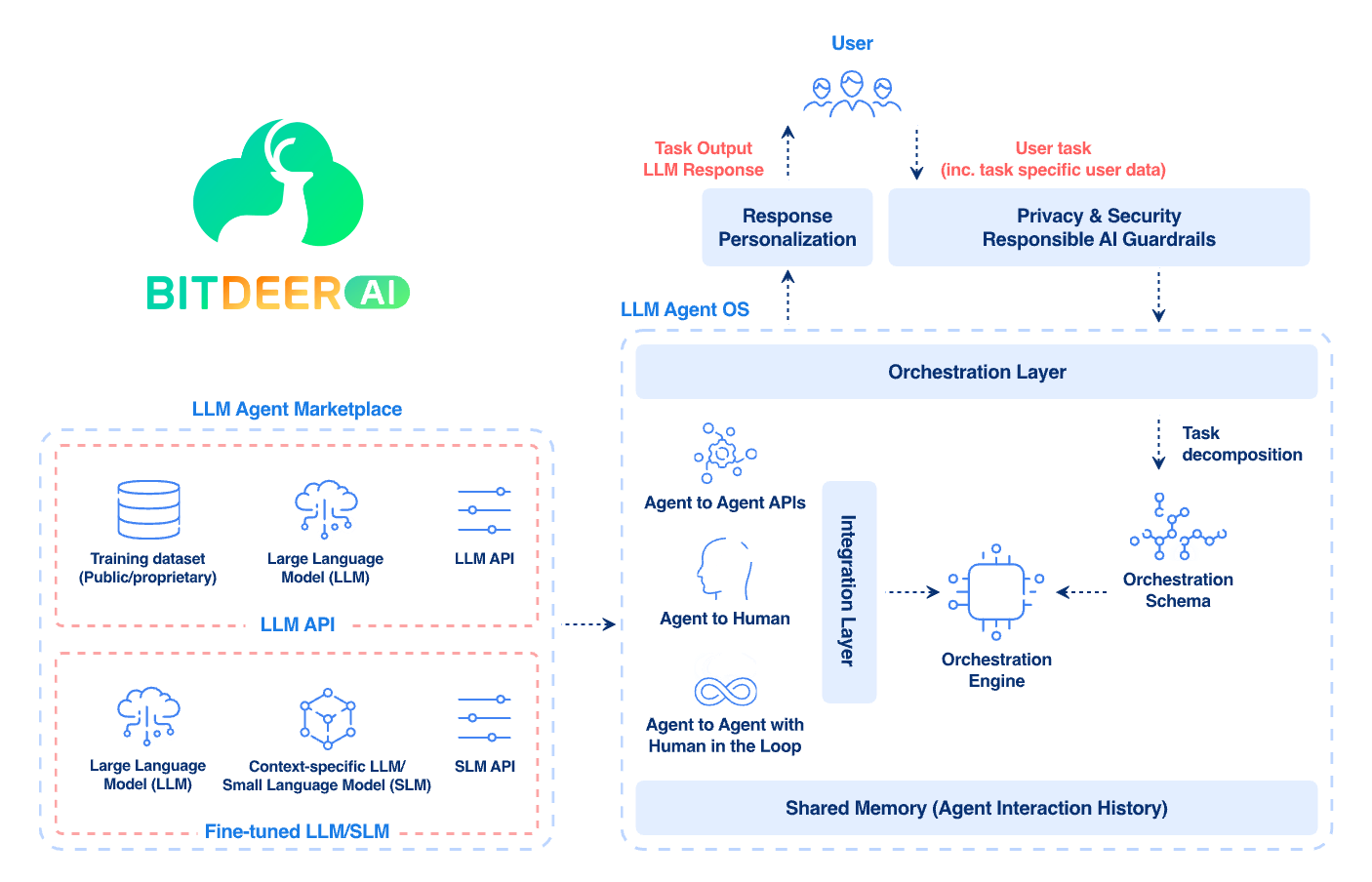
Architecture of Stateful LLMs and AI Agents
A stateful AI system is a stack of components designed to capture, store, and leverage memory effectively. The core elements include:
1. Input Processing and Context Window
The starting point is the LLM’s context window, which handles immediate input and short-term memory. Modern LLMs like Llama 3 or Mistral can process tens of thousands of tokens, but context windows alone aren’t enough for long-term memory; they’re volatile and computationally expensive.
Tip: Use dynamic context pruning to filter relevant information before passing it to the LLM, reducing token bloat.
2. Memory Layer
This is the heart of stateful AI. The memory layer stores interaction history, user profiles, or domain-specific knowledge in a structured format. Common approaches include:
- Vector Databases: Tools like Pinecone or Weaviate store embeddings of past interactions, enabling fast semantic retrieval. For example, a customer support agent might retrieve all prior complaints from a user to inform its response.
- Key-Value Stores: Redis or DynamoDB handle lightweight, structured data like user preferences or session states.
- Graph Databases: Neo4j or ArangoDB model complex relationships, ideal for agents tracking interconnected entities (e.g., supply chain nodes).
Pattern: Combine vector and key-value stores for hybrid memory; vectors for semantic context, key-values for metadata like timestamps or user IDs.
3. State Management and Orchestration
An orchestration layer manages memory retrieval, updates, and integration with the LLM. This is where AI agents shine, acting as controllers that decide when to pull memory, invoke tools, or escalate to humans. Frameworks like LangChain or Haystack provide orchestration logic, while containerized microservices (e.g., via Kubernetes) ensure scalability.
Pattern: Implement a feedback loop with LLM orchestration frameworks to refine LLM relevance via memory updates.
4. Output and Interaction Layer
The final layer delivers responses or actions, often integrating with external systems via APIs (e.g., CRM, ERP). For agents, this might involve executing tasks, like scheduling a meeting or generating a report.
Pattern: Use output templates to ensure consistency while allowing personalization based on memory.
Open-Source Tools for Stateful AI
The open-source ecosystem is rich with tools to build stateful LLMs and AI agents. Here’s a curated stack:
- LLMs
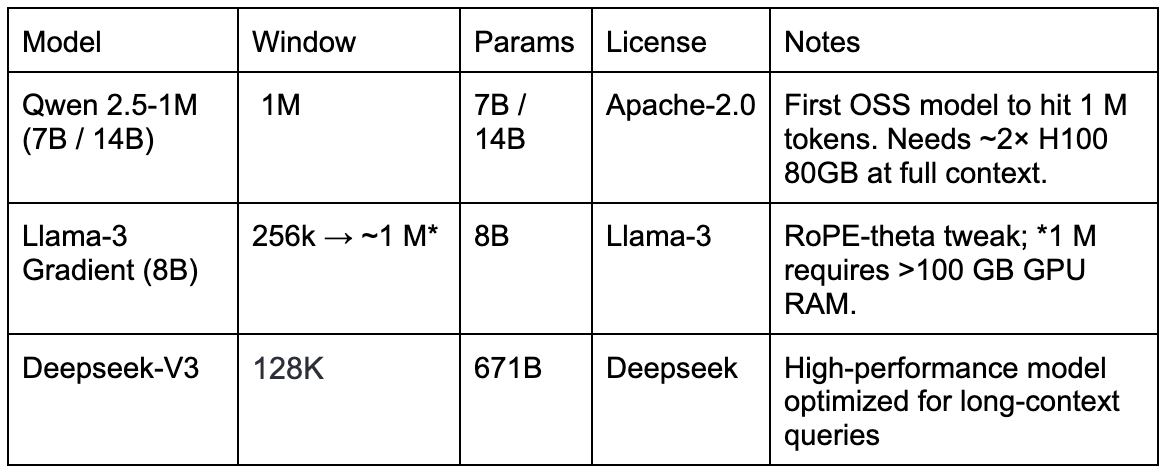
Tip: If you don’t need the full million tokens, 128k–256k models run comfortably on a single H100 80GB node.
- Memory Storage:
- Vector DBs: Weaviate (scalable, with built-in embedding support) or Faiss (lightweight, for research).
- Key-Value Stores: Redis (in-memory, low-latency) or RocksDB (persistent, high-throughput).
- Graph DBs: Neo4j (enterprise-grade) or Dgraph (cloud-native).
- Orchestration: LangChain (agentic workflows, tool integration) or LlamaIndex (data connectors, memory management).
- APIs and Integration: FastAPI for building RESTful endpoints, or Apache Kafka for real-time data streaming.
- Monitoring: Prometheus and Grafana for tracking memory usage, latency, and model performance.
Pro Tip: Start with LangChain for rapid prototyping, then transition to custom orchestration with FastAPI and Kubernetes for production-grade scalability.
Best Practices & Common Pitfalls
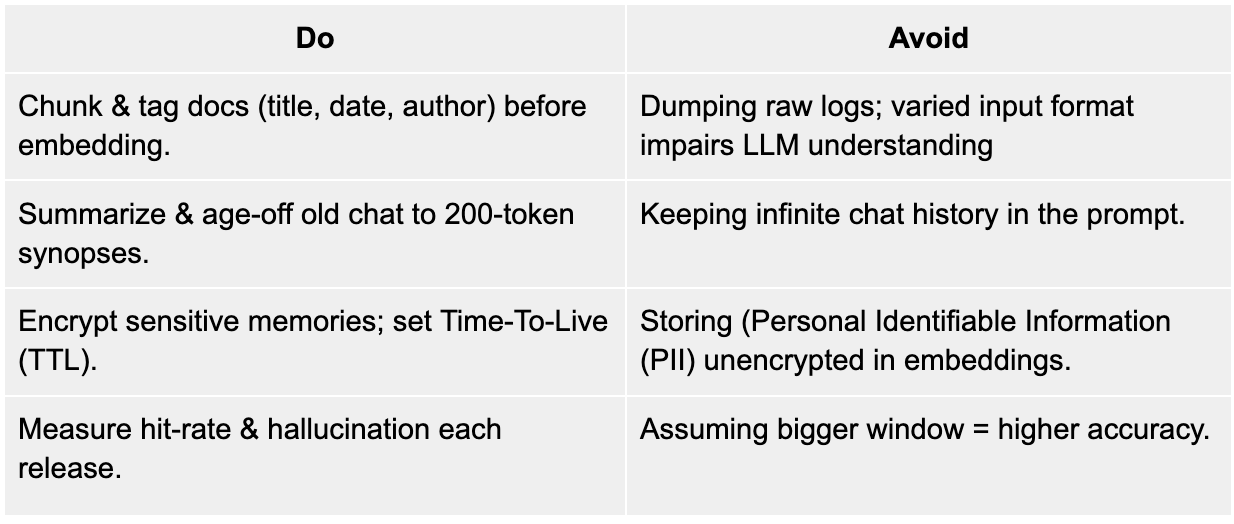
Hands‑on: Building a Long‑Memory Coding Copilot
Scenario: An internal dev assistant must remember architecture decisions over a three‑month sprint.
The Path Forward
Stateful LLMs and AI agents are the next frontier, blending memory with intelligence to create systems that feel human-like in their continuity. AI that doesn’t just answer questions but builds relationships, solves problems, and evolves alongside your business. In a world where context is king, stateful AI is your crown jewel.