Think in Parallel: How Multiverse is Reimagining Language Model Reasoning

Large language models are becoming the driving force behind modern AI systems, but their generation process remains constrained by the mainstream "autoregressive" mechanism. This word-by-word linear generation is simple and effective but inherently unsuitable for handling complex structures and multi-path reasoning tasks. As model sizes grow, computational demands have also increased significantly. Is there a more efficient way to address these challenges?
A recent study jointly conducted by researchers from Carnegie Mellon University's Infini-AI Lab and NVIDIA, supported by GPU resources from Bitdeer AI for both training and inference, offers a promising direction. Their paper, titled Multiverse: Your Language Models Secretly Decide How to Parallelize and Merge Generation, presents a core insight: parallel logic has always existed within language models, but traditional supervised fine-tuning methods have failed to fully leverage it.
The team introduces Multiverse, a novel generative model that enables native parallel generation. Their model, Multiverse-32B, achieves performance comparable to autoregressive LLMs in real-world reasoning tasks, while offering significantly better scalability within the same context thanks to parallel generation. Single-token generation latency can be reduced by up to 2x, depending on the degree of parallelism. Multiverse is a bold exploration that allows the model to autonomously decide when to parallelize, how to parallelize, and how to merge outputs, breaking through long-standing generation bottlenecks.
Improve Model Efficiency
Most mainstream large language models (such as GPT, Gemini, and Claude) are built on an autoregressive architecture, where each token must be generated sequentially. This approach has two major limitations:
- It prevents parallel generation, causing inference efficiency to degrade linearly with sequence length.
- It struggles to handle complex structured reasoning, as all reasoning paths must be compressed into a single linear output.
Previous methods like Tree of Thoughts, Best-of-N, and MCTS have attempted to enable multi-path exploration and answer merging. However, these approaches typically rely on external search algorithms or tools, which can disrupt internal state consistency and lead to context loss and latency issues.
Multiverse offers a key insight: even without explicit parallel generation, current large language models frequently naturally produce parallelizable logical structures during long-form generation—such as analyzing subcomponents of a problem, parallel case reasoning, or unfolding recursive structures. These latent opportunities for parallel reasoning have long been overlooked or linearly compressed by autoregressive models, resulting in significant inefficiencies.
Multiverse: Letting the Model Decide How to Parallelize
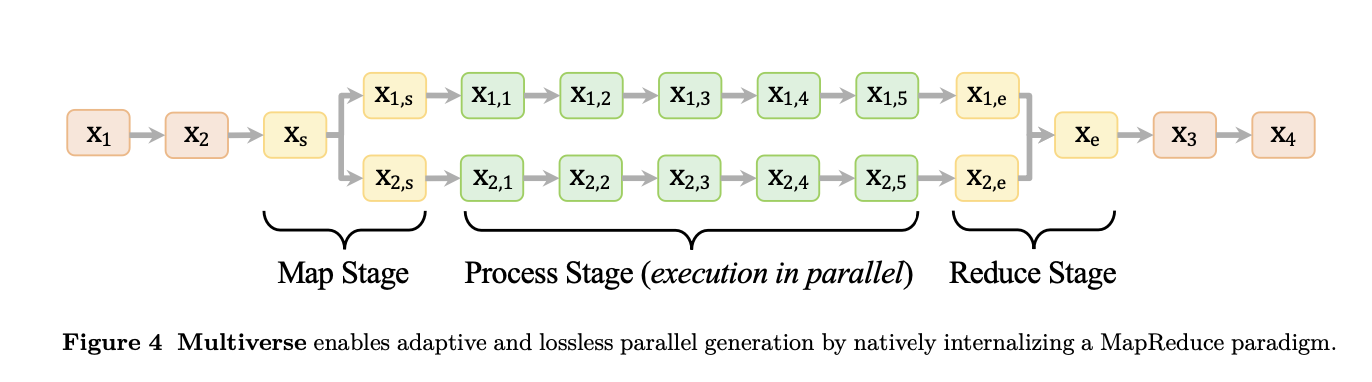
Multiverse is not an external enhancer or search tool. It is a newly designed generative framework built through joint innovations in model architecture, training data, and inference engine. Inspired by the MapReduce paradigm, Multiverse restructures language generation into three native stages:
- Map: The model automatically decomposes complex tasks and generates structured objectives (e.g., “consider three scenarios,” “analyze two directions in parallel”).
- Process: Each subtask is processed along an independent reasoning path, with its own contextual prefix and token stream.
- Reduce: All reasoning branches are seamlessly merged within the model, restoring a unified semantic flow.
Unlike traditional autoregressive models that strictly follow a single sequence, Multiverse acts like a generation agent with internal control logic. It can autonomously identify parallelizable content, decide when to switch generation modes, and fully preserve contextual states throughout.
The key innovation is that this process is entirely native. All parallel scheduling, path merging, and context management are generated and controlled internally by the model itself, without reliance on external modules. This ensures continuity, consistency, and semantic integrity.
From Concept to Real-World Application
Multiverse is not just a new model—it is a full “data-to-deployment” system. To enable real-world deployment, the team developed a complete toolkit, including Multiverse Curator (data generator), Multiverse Attention (core algorithm), and Multiverse Engine (optimization system).
- Data Layer: The team introduced Multiverse Curator, an automated data generation tool that leverages existing large language models to parse sequential reasoning chains into structured trees, identify parallelizable nodes, and convert them into MapReduce-style formats with control tags like <Parallel>, <Goal>, and <Path>. This process eliminates manual labeling and produced the high-quality Multiverse-1K training dataset for structured reasoning.
- Model Layer: A key innovation is Multiverse Attention, a lightweight modification of traditional attention mechanisms. It allows the model to parallelize multiple reasoning paths during the Process phase while keeping each path independent, and to seamlessly merge contexts during the Reduce phase. This design is compatible with existing architectures, requiring only fine-tuning to convert autoregressive models to the Multiverse framework.
- System Layer: Built on the SGLang inference framework, Multiverse Engine supports structured tag recognition and dynamic reasoning path switching. For example, when the model generates a <Parallel> tag, the system instantly allocates parallel threads, and when a <Conclusion> tag appears, it automatically returns to sequential generation. The entire process runs efficiently and autonomously without manual intervention.
This architecture gives Multiverse native support for parallel generation in both training and inference.
Performance Beyond Speed
The final result of this work is Multiverse-32B, a 32B-parameter model fine-tuned from Qwen2.5-32B-Instruct. The entire training process used only 1,000 structured samples and was completed within 3 hours on 8 B200 GPUs.
Key findings:
- Significant Accuracy Gains: Multiverse-32B achieved performance comparable to or better than leading autoregressive baselines on complex reasoning benchmarks such as AIME24, AIME25, MATH500, and GPQA.
- Higher Parallelism: The model reached a parallel generation degree of approximately 1.18 (on AIME24), meaning more valid tokens are generated per unit of generation length compared to autoregressive baselines.
- Double Generation Efficiency: Multiverse achieved up to 2x faster inference under the same context budget compared to traditional models, with no loss—and in some cases, improvement—in accuracy.
- Strong Scalability: The model maintained stable acceleration and efficient memory utilization even when scaling the batch size up to 128.
These results not only prove that parallel reasoning is feasible but also demonstrate that it can improve efficiency and reduce latency without compromising quality, paving the way for next-generation real-time inference systems.
Conclusion
Multiverse significantly improves GPU utilization through large-scale parallel generation. It shows particular advantages in small-batch and long-context inference scenarios, effectively reducing both latency and energy consumption. It also achieves near-constant total latency for tasks that are typically difficult to parallelize, even as task complexity increases.
The future of AI should go beyond simple generation. It should include structural control, path scheduling, and task planning. Multiverse offers a promising direction, demonstrating that language models can not only understand language but also organize and manage their own reasoning processes. With the open-source release of Multiverse and the continued development of similar models, this approach is expected to see broader adoption in areas such as automated workflows, code generation, and multi-step decision-making.
Compute power is essential not only for AI research but also for deploying algorithms at scale. We are proud to have provided GPU resources for this project. In the future, Bitdeer AI will continue to support the training of general-purpose intelligent models and help advance the joint development of generative AI in both performance and reasoning capabilities.