Unlocking AI Potential with NVIDIA GB200 NVL72

The rapid advancements in artificial intelligence require cutting-edge hardware capable of handling the immense computational demands of machine learning , deep learning , and AI-driven workloads. One of the most anticipated breakthroughs in this domain is the NVIDIA GB200 NVL72, a GPU designed specifically to meet the needs of high-performance computing and AI workloads. Leveraging the power of NVIDIA's innovative architectures, the NVIDIA GB200 NVL72 is poised to revolutionize AI development.
What is NVIDIA GB200 NVL72?
The NVIDIA GB200 NVL72 is a rack-scale AI system designed for large-scale AI training and inference workloads. Built on NVIDIA’s Blackwell architecture, it features 36 Grace Blackwell Superchips, each integrating one NVIDIA Grace CPU and two Blackwell GPUs, totaling 72 GPUs and 36 CPUs in a single liquid-cooled rack.
Through a full NVLink and NVLink Switch interconnect, all GPUs operate as a tightly coupled system, allowing the platform to function as a single, massive GPU rather than a collection of discrete accelerators. This architecture significantly reduces inter-GPU communication overhead and is optimized for workloads that involve large model sizes, frequent parameter exchange, and long-running training or inference jobs that require stable, predictable performance at scale.
Technical evolution from H100 to GB200 NVL72
While H100 marked a major step forward for transformer-based AI, GB200 NVL72 builds on that foundation with system-level changes. Compared with H100, GB200 NVL72 introduces next-generation Tensor Cores and an updated second-generation Transformer Engine optimized for new FP4 precision, which enables doubling the compute capacity and model size compared to the H100’s FP8, specifically benefiting massive LLM inference. This directly benefits LLM training and inference, where matrix operations dominate runtime.
Interconnect is another key differentiator. H100 clusters rely on NVLink within nodes and high-speed networking across nodes, which can introduce latency and synchronization overhead at scale. GB200 NVL72 extends the NVLink domain to all 72 GPUs within the rack via the NVLink Switch System, offering 9x the aggregate bandwidth of previous generations and treating the entire rack as a single GPU.
Memory access patterns also improve at the system level. By enabling faster parameter sharing and collective operations, GB200 NVL72 improves utilization efficiency, especially for models that exceed the memory capacity of a single GPU. Finally, GB200 NVL72 is a liquid-cooled-native system. This shift is essential to handle the 120kW+ rack power density, ensuring sustained peak performance that would be physically impossible to achieve with traditional air-cooling.
These architectural changes are not only reflected in design principles, but also translate directly into measurable gains in real-world AI workloads. The following benchmarks illustrate how GB200 NVL72 compares with H100-based systems across large language model training, inference throughput, energy efficiency, and data processing performance.
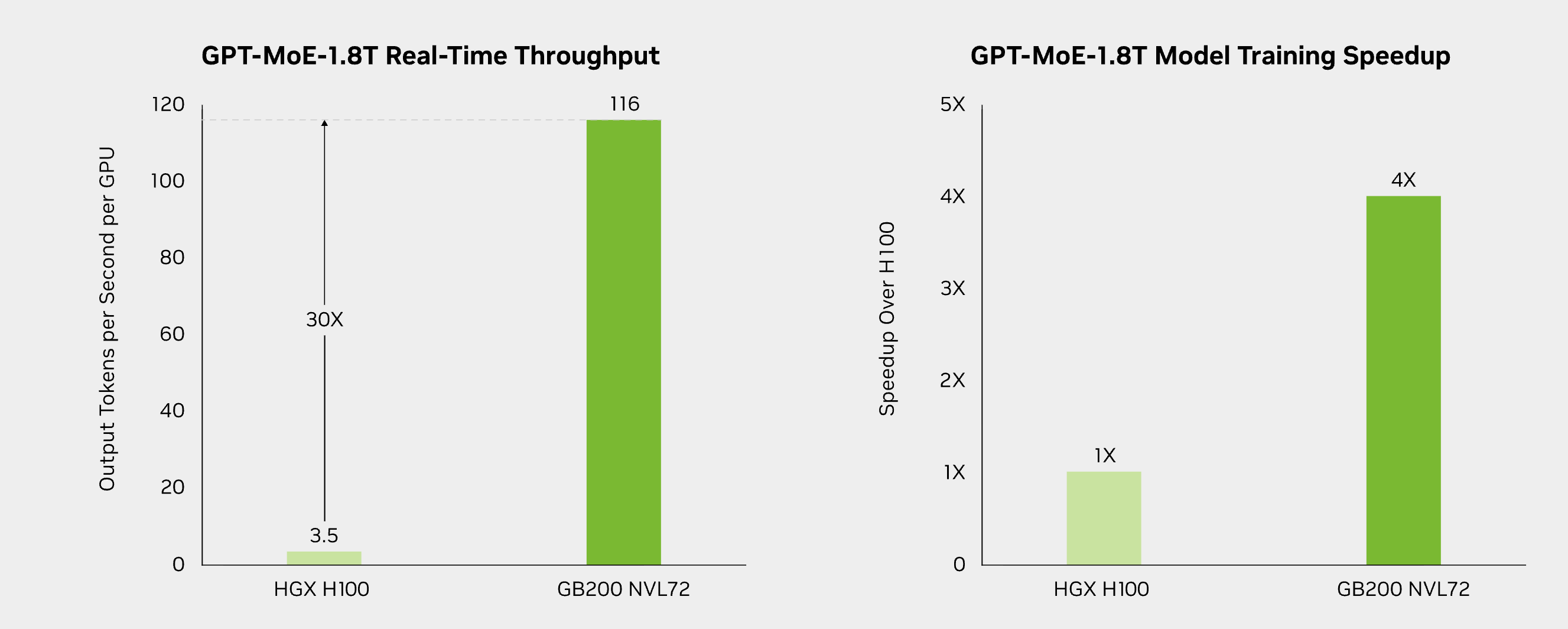
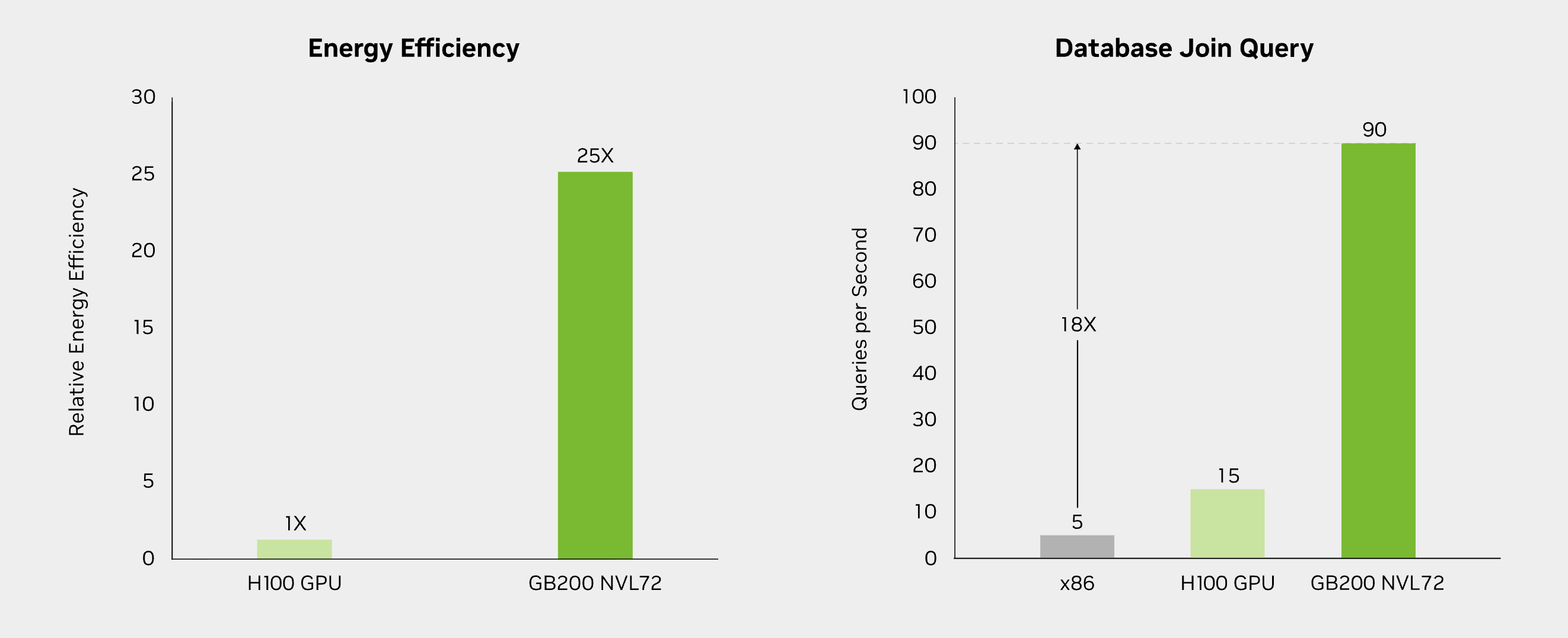
source: from NVIDIA website
Business Use Cases: Where GB200 NVL72 Fits Best
The NVIDIA GB200 NVL72 is designed for AI workloads that require high computational throughput, efficient scaling, and sustained performance. Its rack-scale architecture supports enterprise scenarios where training speed, inference efficiency, and operational cost have a direct impact on business outcomes across multiple industries, including healthcare, finance, and AI-native technology companies.
Large-Scale AI Model Training
NVIDIA GB200 NVL72 is well suited for training large and complex AI models used in areas such as autonomous driving, healthcare, robotics, and natural language processing. With powerful Tensor Cores and increased system-level throughput, the platform reduces the time required to train deep learning models, enabling faster experimentation cycles and quicker progression from research to deployment.
High-Performance AI Inference
Beyond training, NVIDIA GB200 NVL72 supports inference workloads that demand fast and reliable response times. Applications such as video analytics, recommendation systems, and real-time decision support benefit from the platform’s ability to execute inference workloads efficiently at scale, helping enterprises deliver more responsive AI-powered services. And in healthcare and life sciences, workloads like medical imaging models, genomics analysis, and drug discovery rely on large datasets and long-running training jobs. It can help reduce training time and improve resource utilization, enabling faster experimentation and more efficient progression from research to clinical or production environments.
Energy-Efficient AI at Scale
NVIDIA GB200 NVL72 is designed to balance performance with efficiency, making it suitable for large-scale AI deployments where power consumption and operating costs are key considerations. This is particularly relevant for cloud providers, enterprise AI platforms, and research institutions running continuous workloads, where efficiency at scale directly affects total cost of ownership.
Enabling Next-Generation AI Applications
By supporting massive datasets and increasingly complex models, NVIDIA GB200 NVL72 enables organizations to develop and deploy next-generation AI applications across industries. This includes multimodal AI systems, large shared foundation models, and AI platforms that serve multiple business units or customers. The platform allows enterprises to scale AI capabilities incrementally while maintaining performance and architectural consistency as model complexity grows.
Bitdeer AI and NVIDIA GB200 NVL72 Clusters
As part of our ongoing expansion of the NVIDIA GPU offerings on Bitdeer AI Cloud platform, the addition of NVIDIA GB200 NVL72 extends the platform’s ability to support larger and more communication-intensive AI workloads. At the same time, NVIDIA H100 remains an integral part of our platform, continuing to support a wide spectrum of training and inference use cases. Together, these GPU models form a complementary compute foundation that addresses different model sizes and deployment needs.
By offering both platforms, Bitdeer AI allows customers to select GPU configurations that best match their model size, workload characteristics, and operational requirements.