PostgreSQL OLAP Use Case
This guide provides a comprehensive walkthrough for setting up and using PostgreSQL for OLAP (Online Analytical Processing) workloads using the pg_analytics extension. The extension enhances PostgreSQL with advanced analytics capabilities including direct integration with S3 storage for efficient data processing.
Prerequisites
Before starting, ensure you have:
- Access to a PostgreSQL RDS instance with superuser privileges
- S3 bucket access with proper credentials
- MinIO client (mc) installed for S3 operations
- Basic knowledge of SQL and PostgreSQL
Step 1: Create Analytics Database
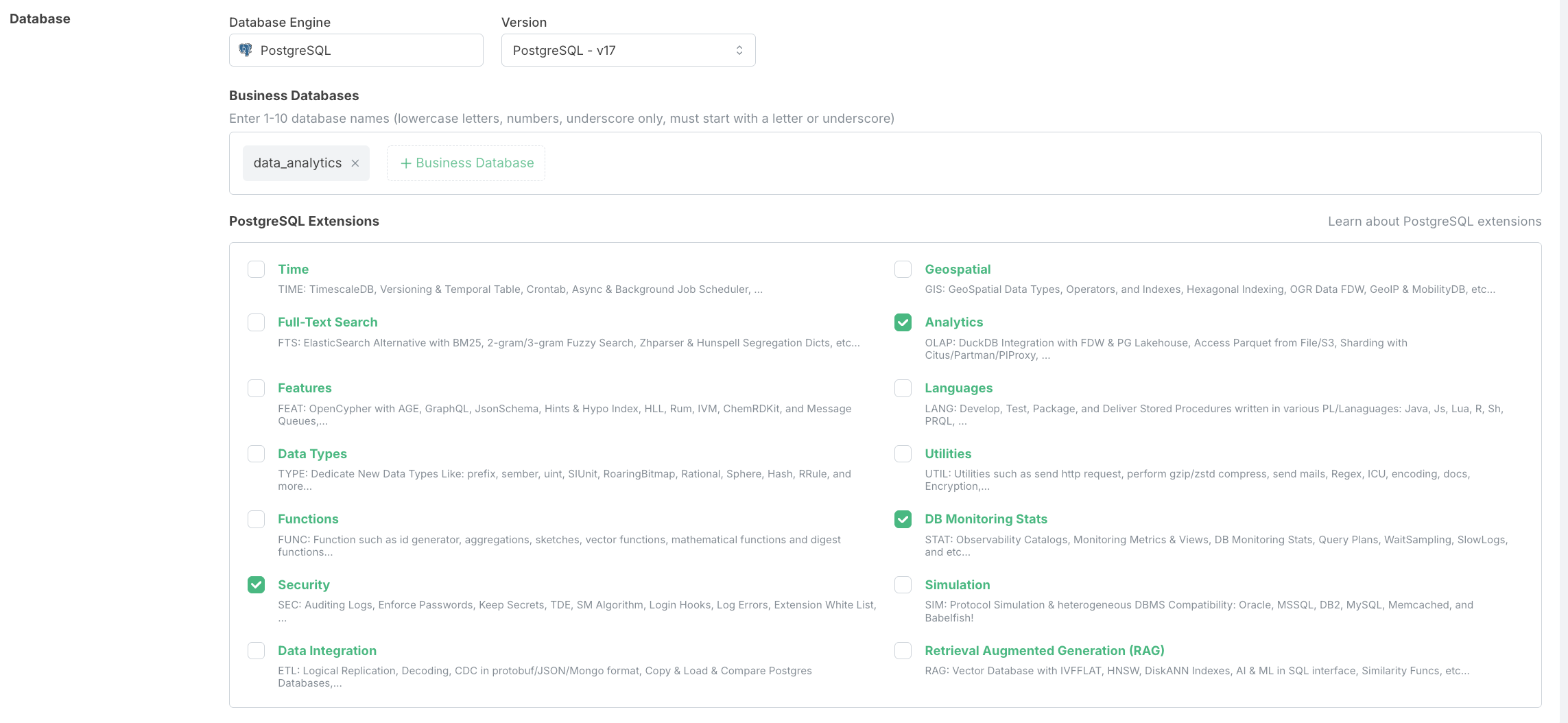
First, create a dedicated RDS database with OLAP analytics features enabled. Using a separate database for analytics helps isolate these workloads from transactional processing.
Create database data_analytics along with the OLAP extension.
Step 2: Set Up Foreign Data Wrapper for Parquet Files
PostgreSQL's Foreign Data Wrapper (FDW) mechanism allows you to query external data sources as if they were regular PostgreSQL tables. Here we set up a wrapper for Parquet files, a columnar storage format optimized for analytics.
-- Create a foreign data wrapper for parquet files
-- This defines how PostgreSQL will interact with parquet files
create foreign data wrapper parquet_wrapper
handler parquet_fdw_handler validator parquet_fdw_validator;
-- Create a server definition that uses the parquet wrapper
-- This server will be used for all parquet file connections
create server parquet_server foreign data wrapper parquet_wrapper;
Step 3: Configure S3 Access
To access data stored in S3, we need to create a user mapping that includes the necessary credentials and connection details.
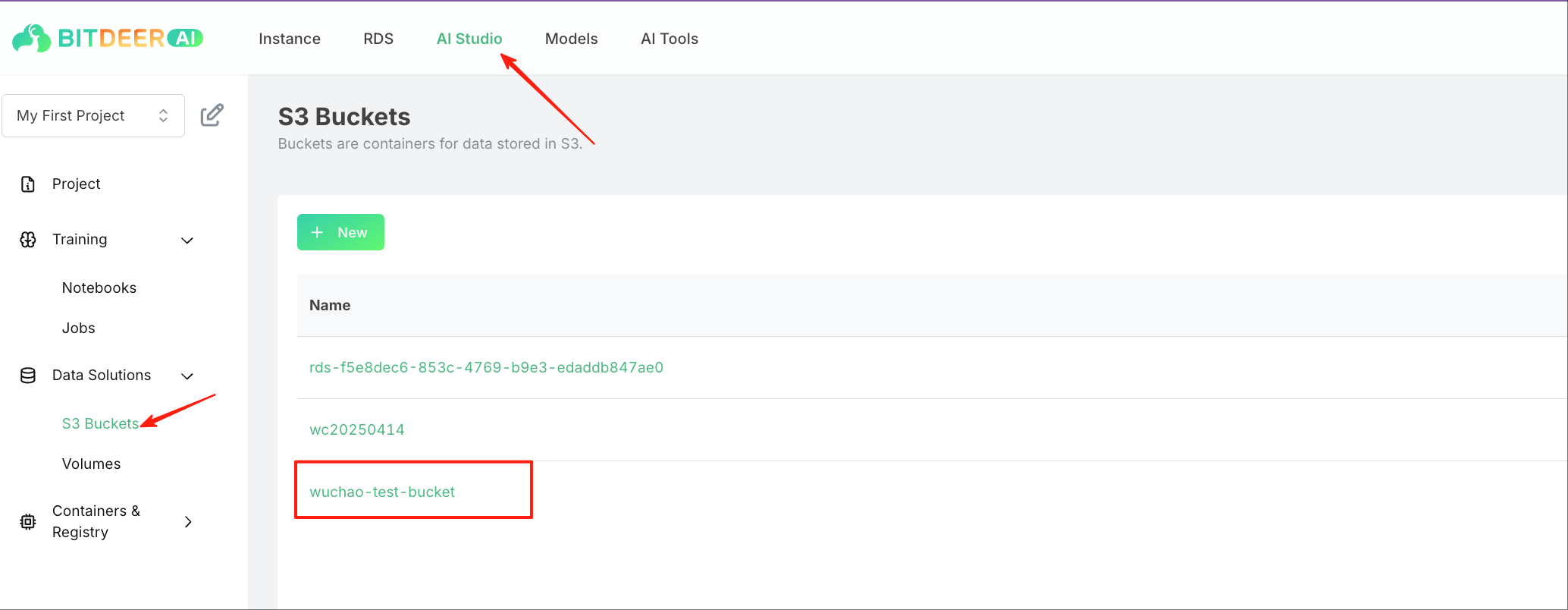
First, we navigate to our s3-bucket in our cloud, to make sure the bucket exists:
-- Create a mapping between the PostgreSQL user and the S3 credentials
-- This allows PostgreSQL to authenticate with the S3 service
create user mapping for root
server parquet_server
options (
type 'S3', -- Specify we're connecting to S3
key_id 'ak-crsg...', -- Your S3 access key
secret 'sk-crsg...', -- Your S3 secret key
region 'ap-southeast-1', -- S3 region where your bucket is located
endpoint 'dl.bitdeer.ai', -- Custom S3 endpoint (for MinIO or custom S3)
url_style 'path', -- URL style for S3 requests (path or virtual-hosted)
use_ssl 'true' -- Enable SSL for secure connections
);
Step 4: Prepare Sample Data
For this tutorial, we'll use a publicly available dataset from Huggingface. This dataset contains food images with metadata in Parquet format, which is ideal for analytics workloads.
Now let's prepare some sample testing data from huggingface:
https://huggingface.co/datasets/Codatta/MM-Food-100K/tree/refs%2Fconvert%2Fparquet/default/train.
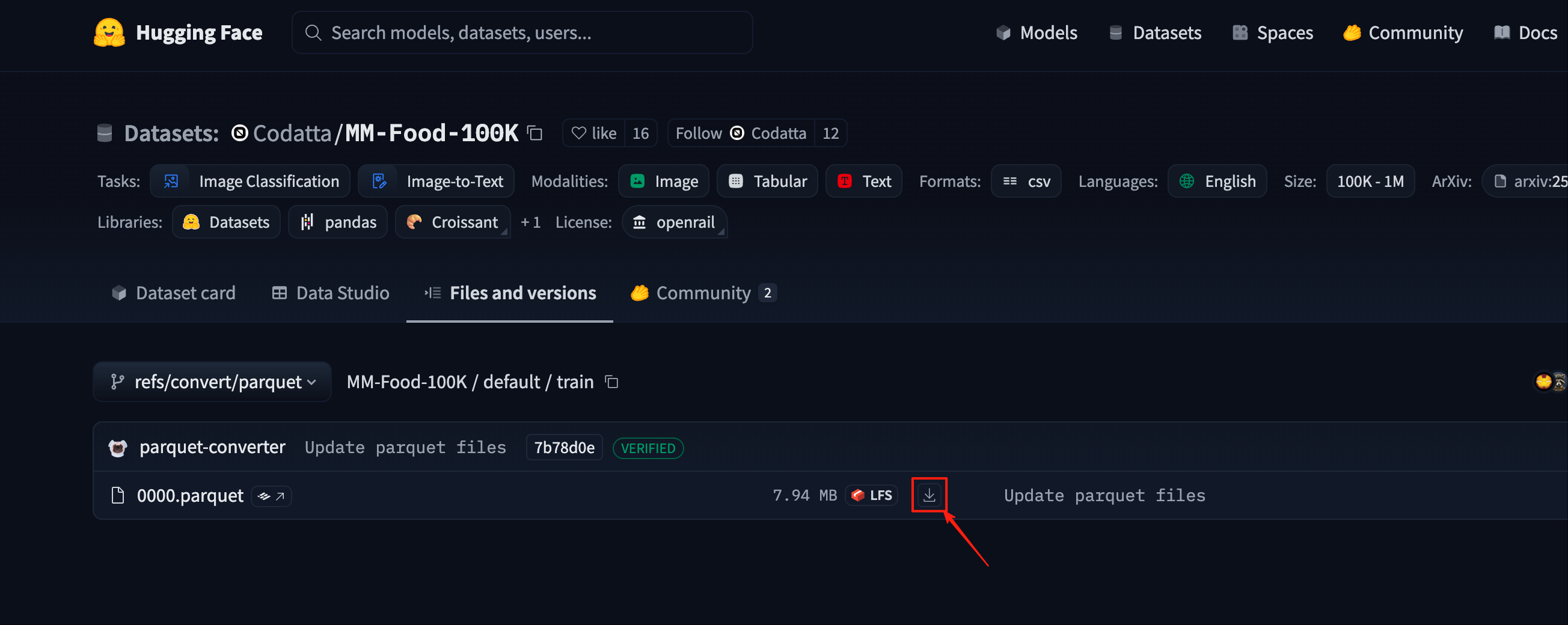
Download the dataset according to the screenshot:
Use the following command line to upload the dataset to our S3 bucket. The MinIO client (mc) provides a convenient way to interact with S3-compatible storage.
# copy the parquet file downloaded to the bucket of your choice
# Format: mc cp <source_file> <target_bucket>/<target_path>
mc cp 0000.parquet bitdeer-test/wuchao-test-bucket/mm-food-100k.parquet
Step 5: Create Foreign Table
Now we'll create a foreign table that maps to the Parquet file in S3. This allows us to query the data directly without importing it into PostgreSQL.
-- Create a foreign table that maps to the parquet file in S3
-- The empty parentheses () mean we'll use the schema from the parquet file
create foreign table train_data()
server parquet_server
options (files 's3://wuchao-test-bucket/mm-food-100k.parquet');
The empty parentheses in the table definition are intentional - the pg_analytics extension will automatically detect the schema from the Parquet file metadata. This is a powerful feature that allows you to work with external data without having to manually define all columns.
Step 6: Verify Setup
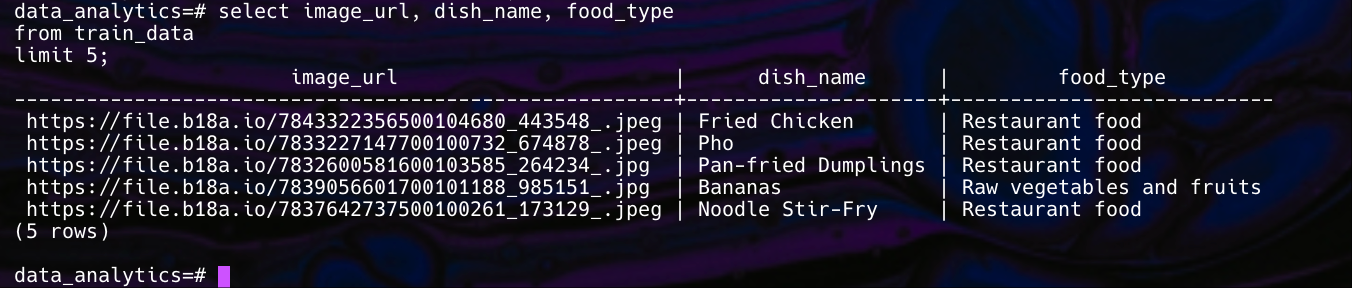
Let's run a simple query to verify that our setup works correctly and we can access the data.
-- Query the foreign table to verify the setup
-- We select key columns to understand the data structure
select image_url, dish_name, food_type
from train_data
limit 5;
This query should return the first 5 rows from our dataset, showing the image URLs, dish names, and food types. The results should look similar to the screenshot:
Conclusion
This guide demonstrates how to set up and use PostgreSQL with the pg_analytics extension for advanced analytics capabilities. By leveraging foreign data wrappers for parquet files stored in S3, we can perform sophisticated analytics on large datasets without having to load all the data into PostgreSQL tables.
Key benefits of this approach:
- Direct querying of data in S3 without full import
For production deployments, consider:
- Setting up proper access controls for S3 credentials
- Implementing query monitoring and optimization
- Creating appropriate indexes for common query patterns
- Scheduling regular maintenance tasks
- Setting up proper backup strategies for materialized views and other derived data