一键模型部署:Bitdeer AI 上的 NVIDIA NIM 实践

随着人工智能从基于提示的工具向自主系统演进,构建可扩展、模块化的基础设施已成为关键需求。NVIDIA推理微服务(NIMs)为此提供了高效的解决方案,助力开发者和企业快速可靠地部署强大的开源基础模型。
作为NVIDIA NIMs官方授权合作伙伴,Bitdeer AI平台为用户提供精选的NVIDIA NIM容器集合。这些容器支持业界领先的大模型,包括gpt-oss-120b、LLaMA 4、Mixtral以及多种基于检索的嵌入模型。通过Bitdeer AI Studio界面,用户仅需简单点击即可完成部署。
什么是NVIDIA NIMs
NVIDIA NIMs(推理微服务)是一种容器化的AI推理解决方案,它将预训练好的AI模型与所有必要的依赖项及优化运行时环境打包成可独立部署的单元。作为NVIDIA AI Enterprise套件的一部分,这些预构建的Docker容器专为GPU基础设施的高效推理而设计。每个NIM均提供行业标准API,可无缝集成至AI应用和开发流程,并根据特定的基础模型与GPU组合优化响应延迟和吞吐量。
借助NIMs,开发者无需手动配置运行时环境、管理模型依赖或部署推理服务器。每个容器均具备生产就绪性,并采用NVIDIA的TensorRT和Triton等推理技术进行优化,从而为大型语言模型(LLM)、视觉语言模型(VLM)及嵌入流水线提供低延迟、高吞吐的推理服务。

来源:NVIDIA
部署用例
NVIDIA NIMs 为文本、视觉和多模态AI工作负载解锁了多种企业级应用场景:
- 企业聊天助手:部署基于LLaMA的指令调优模型,用于内部知识检索、IT服务台自动化和客户支持,可提高响应准确性并降低支持成本。
- 视觉语言理解:使用诸如mistral-small-3.2-24b等模型执行图像描述、视觉问答、产品标记和多模态搜索等任务,这对电子商务、媒体和数字资产管理至关重要。
- 内容审核与文档处理流水线:构建可扩展的流水线,用于实时内容审核、文档分类、翻译和批量摘要,适用于媒体、社交平台和全球企业通信等行业。
- 垂直领域多模态助手:开发特定领域的AI助手,能够处理和推理多种数据类型(文本、图像和表格数据),应用于金融(如收益分析)、医疗(如临床决策支持)和零售(如库存和客户洞察)等领域。
如何在Bitdeer AI上部署NVIDIA NIMs
作为NVIDIA NIM的授权提供商,Bitdeer AI已将不断增长的NVIDIA NIM库直接集成到我们AI Studio的容器注册表服务中。用户可以在几秒钟内搜索模型、预览配置并启动GPU加速的推理pod。无需管理容器、手动配置Kubernetes或调配GPU。无需构建容器。无需管理集群。只需简单操作即可运行。.
Bitdeer AI 支持模型列表
Bitdeer AI 支持多种模型。这些NIM可用于广泛的任务,包括文本生成、多模态理解、文档摘要、向量嵌入、图文对齐和检索增强生成。以下是一些示例:
- openai/gpt-oss-120b
- meta/llama-3.1-8b-instruct
- meta/llama-3.3-70b-instruct
- mistralai/mistral-7b-instruct-v0.3
- nvidia/nv-embedqa-e5-v5-pb25h1
- nvidia/nv-rerankqa-mistral-4b-v3

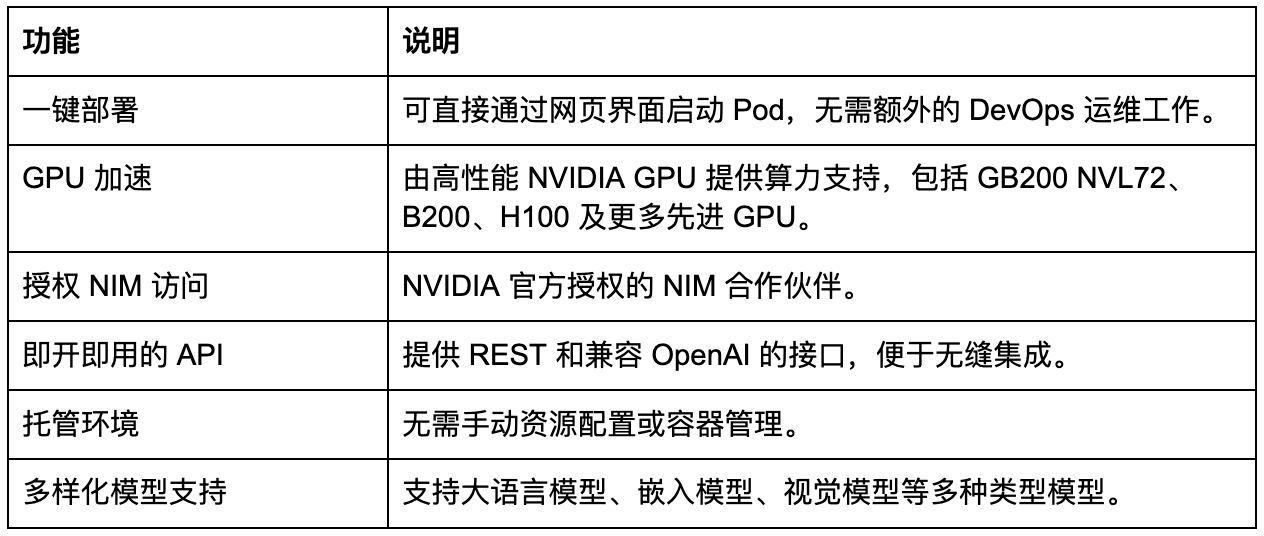
Bitdeer AI助力NIM部署的优势
Bitdeer AI 提供全托管环境,使 NIM 部署快速、稳定且易于访问。其设计旨在降低运维负担,同时在多样化的工作负载中实现性能最大化。
快速入门指南
在Bitdeer AI上部署NIM容器的步骤如下:
- 登录 Bitdeer AI Studio
- 进入 AI Studio 并选择容器注册表(Container Registry)
- 选择一个模型,例如 openai/gpt-oss-120b
- 点击“启动 Pod”(Launch Pod)
- 开始向专属端点发送请求
以下是视频演示及逐步操作指南。
总结
借助 Bitdeer AI 与 NVIDIA NIMs,部署基础模型不再是复杂且耗时的过程。开发者可以在数分钟内完成从模型选择到生产级推理的整个流程。无论是用于原型开发、批量处理,还是驱动智能应用,Bitdeer AI 都能够在可扩展且可靠的环境中轻松实现前沿模型的落地与应用。