Bitdeer AI Cloud:基于 NVIDIA OpenShell 的可扩展智能体部署

近期,OpenClaw 的出现引发了业界对一类新型 AI 系统日益增长需求的关注。这类系统通常被称为“claws”,代表着一种可长时间运行、自主执行、并能够自我演进的智能体。它们能够在几乎无需用户持续干预的情况下,规划并执行多步骤工作流。与传统 AI 助手不同,claws 并不局限于单轮交互。它们可以访问本地文件,与应用程序及外部工具进行交互,并动态编排多个子智能体,对复杂任务进行拆解与协同执行。更重要的是,这类系统还能够持续优化策略,决定任务应在何处执行,并随着时间推移不断提升整体执行效果。
与此同时,这一演进也带来了新的挑战。随着智能体被赋予更广泛的数据、工具和基础设施访问能力,安全性、隐私性与治理相关的问题变得愈发关键。围绕访问控制、数据流转、模型调用以及执行边界的种种问题,已经不再只是理论讨论,而是决定这类系统能否安全落地到生产环境中的核心前提。
为应对市场对于更安全、可控的智能体执行环境不断增长的需求,NVIDIA 在 GTC 2026 上推出了面向 OpenClaw 的 NVIDIA NemoClaw。这是一个开源技术栈,旨在为长时间运行的自主智能体引入隐私与安全控制能力。NemoClaw 基于 NVIDIA Agent Toolkit 构建,作为一个集成层,使 OpenClaw 智能体能够运行在全新推出的 NVIDIA OpenShell 运行时之上。通过将NVIDIA Nemotron等开放模型与受控执行环境相结合,NemoClaw 让常驻型、持续运行的智能体在实际部署中更安全,也更具可行性。
NVIDIA OpenShell:为 NemoClaw 提供更安全的智能体执行基础
NVIDIA OpenShell 是一个开源运行时,旨在让自主 AI 智能体的部署更安全、更具实际落地可行性。其核心作用在于充当智能体与底层基础设施之间的控制层,对智能体的执行方式、可访问资源范围以及推理请求的路由路径进行统一治理。
与仅依赖提示词约束或智能体内部内置护栏机制不同,OpenShell 将策略执行下沉至运行时层面进行强制实施。它通过在隐私、安全和基础设施访问边界上提供更清晰的控制能力,帮助开发者弥合从实验验证到生产部署之间的落差,使自主、自演进的智能体能够以更可控的方式落地到真实环境中。
OpenShell 如何构建面向安全的智能体运行环境
OpenShell 通过一个网关统一管理一个或多个相互隔离的沙箱环境,智能体在这些受控沙箱中运行。要理解其工作机制,可以从两个互补维度进行分析:核心组件(components)与防护层(protection layers)。前者定义系统的结构与控制方式,后者则明确策略在何处被执行与生效。
- 网关(Gateway) 作为控制平面,负责协调沙箱生命周期管理、身份认证、服务提供方接入以及策略编排与分发。
- 沙箱(Sandbox) 是智能体执行的隔离运行时环境。内置策略引擎对文件系统、网络访问及进程行为实施细粒度约束与强制执行。
- 隐私路由器(Privacy Router) 负责推理请求的路由治理,在对敏感上下文进行更严格控制的同时,根据预设的隐私与成本策略对模型调用路径进行动态调度。
上述组件在四个关键防护层面实施统一控制:文件系统、网络、进程以及推理。其中,文件系统与进程层的控制在沙箱创建时即被固化,以确保执行环境的不可变性;而网络与推理层的控制则支持运行时动态调整,以适应不同策略与业务需求。该架构形成了典型的纵深防御(defense-in-depth)体系,在支持长时间运行的自主智能体的同时,实现对隐私、安全与治理边界的精细化管控。
为进一步理解 OpenShell 如何支撑更安全的自主智能体执行,其整体架构设计尤为关键。下图展示了各核心组件如何协同工作,以实现执行治理、策略强制与推理控制的统一闭环。
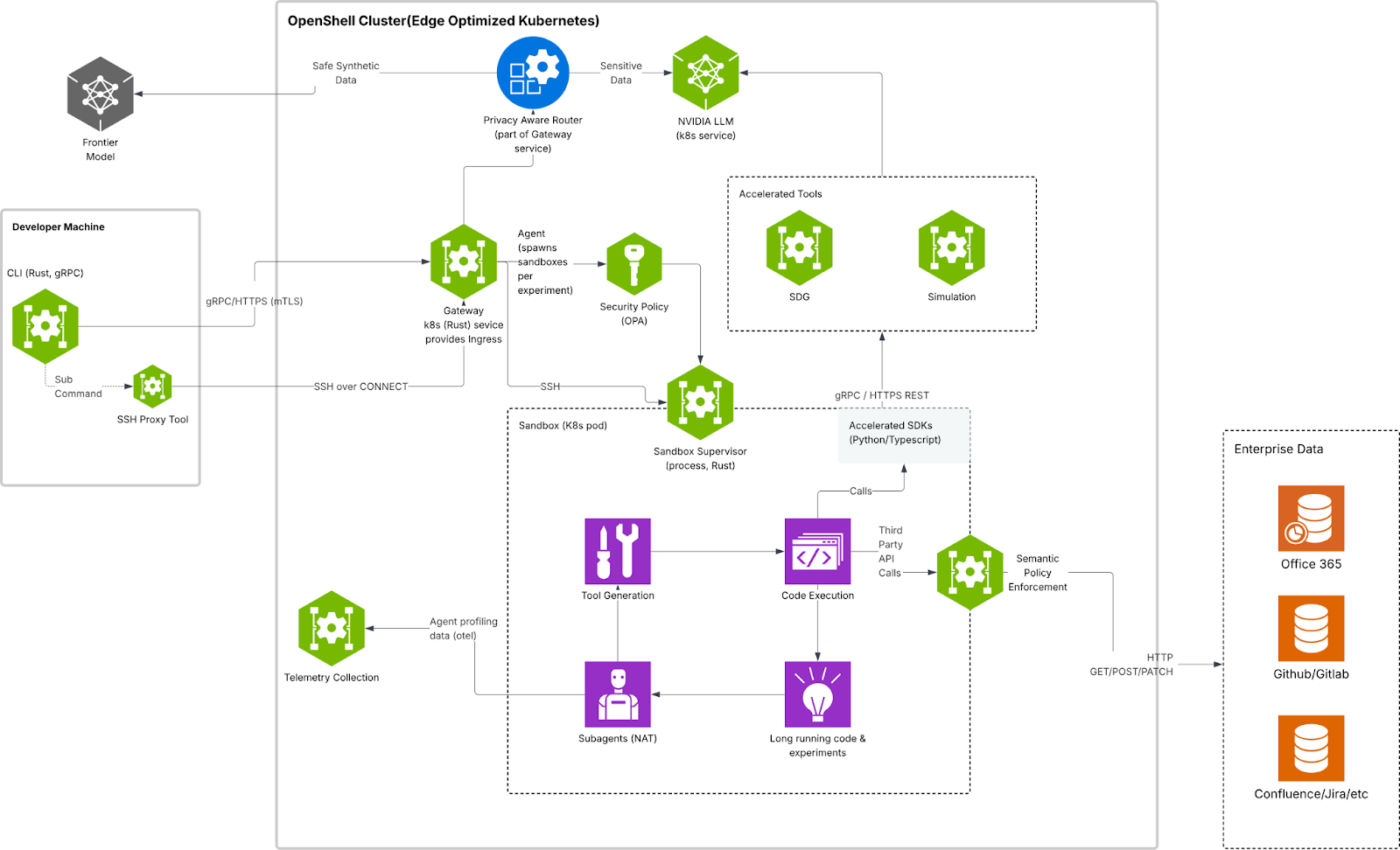
OpenShell 面向更安全自主智能体的架构示意图,展示其核心组件:沙箱、策略引擎与隐私路由器
在 Bitdeer AI Cloud 上部署 AI 智能体
Bitdeer AI Cloud 是亚太地区的第一批 NVIDIA Cloud Partner(NCP) 之一,并作为区域内的模型提供方(model provider)接入 NVIDIA 生态,支持基于 OpenShell 的智能体工作负载在模型部署与推理层面的运行。

Bitdeer AI Cloud 提供多样化的高性能 NVIDIA AI 基础设施,包括 NVIDIA GB200 NVL72, NVIDIA HGX H200 等。用户可在多种 GPU 配置上部署工作负载,并通过内置的负载均衡与动态扩展能力,在性能、成本与可用性之间实现优化。
这使开发者能够以生产级所需的性能与可靠性,支撑智能体工作负载所依赖的模型部署与推理能力。
如何开始
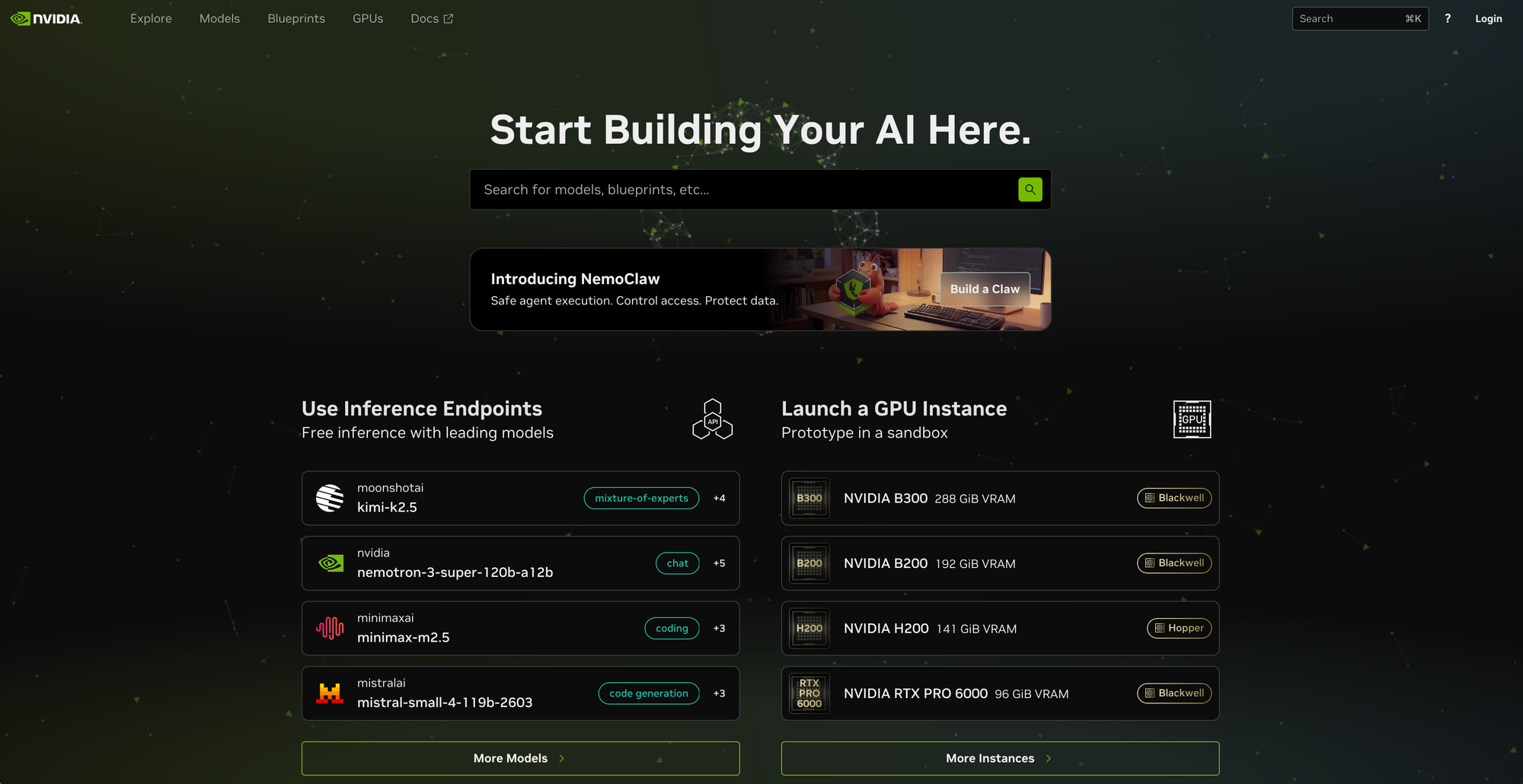
在 Bitdeer AI Cloud 上运行模型流程简洁高效。开发者可在 build.nvidia.com 上启动构建,并将工作负载部署至 Bitdeer AI Cloud:
首先,从 NVIDIA 模型目录中选择所需模型,例如 Kimi K2.5 或 Nemotron 3 Super,并进入 Deploy 页面
随后,在 Partner Endpoints 中选择 Bitdeer AI 作为模型提供方。此举将使智能体工作负载所依赖的底层模型部署与推理运行在 Bitdeer AI Cloud 上,由可扩展、生产级的 NVIDIA AI 基础设施提供支撑。
完成选择后,开发者可根据业务需求,使用无服务器端点(serverless endpoints)或基于专用 GPU 的基础设施进行部署。
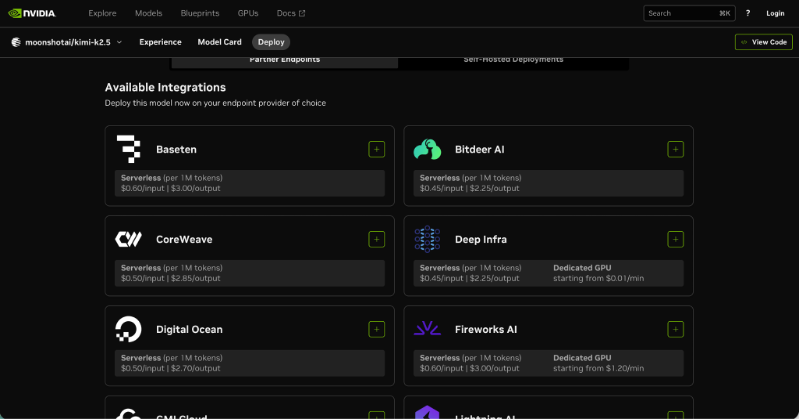
在此基础上,基于 OpenShell 的智能体可执行任务、调用工具,并在受控环境中运行,同时依托可扩展的生产级算力实现稳定执行。
通过将 NVIDIA OpenShell 的安全运行时与 Bitdeer AI 的基础设施能力相结合,开发者可以:
- 在专用高性能 GPU 集群上运行长时任务智能体
- 无需管理底层基础设施即可实现工作负载弹性扩展
- 在隐私、安全与推理路由方面获得更强的控制能力
这一集成有效打通了智能体开发与真实业务部署之间的路径,使开发者能够更轻松地从实验阶段迈向可规模化的生产系统。
总结
在 NVIDIA GTC 2026 上,一个尤为突出的趋势是,AI 正在从基于提示词的交互模式,演进为可长时间运行的自主系统。随着 token 消耗持续增长,其驱动力也越来越多地来自智能体本身,它们在更长上下文中进行推理、协调工具调用,并持续执行复杂任务。
这一演进带来的新要求,已不再局限于模型性能本身。智能体如何执行、数据如何治理,以及系统如何在生产环境中保持可控性,正变得同等重要。NVIDIA OpenShell 正是这一趋势的体现,它通过引入一个运行时层,为智能体执行提供了更安全、更结构化的控制机制。
在 OpenShell 为智能体执行引入更安全运行时层的同时,Bitdeer AI Cloud 则作为模型提供方,提供支撑这类系统在真实环境中落地所需的可扩展算力基础。通过提供可扩展的高性能 AI 计算能力,我们希望帮助开发者在更加重视隐私、安全与可靠性的环境中,构建并运行可长时间执行的智能体系统。
来源:
- NVIDIA 开发者指南: https://docs.nvidia.com/openshell/latest/about/overview.html
- NVIDIA 博客:https://developer.nvidia.com/blog/run-autonomous-self-evolving-agents-more-safely-with-nvidia-openshell/