现代GPU散热方案:从风冷到冷板液冷

随着 GPU 从游戏加速器演变为支撑万亿参数 AI 模型的核心计算平台,散热设计也从过去的边缘问题转变为系统架构的核心组成部分。近年来 GPU 的热设计功耗(TDP)急剧上升,使得冷却方案不再是“风冷或液冷”的简单二选一,而是涉及性能、能效、部署密度及整体运维成本之间的复杂权衡。
在推动这场转变的企业中,NVIDIA 扮演了关键角色。其高功耗 GPU 架构有效地设定了数据中心硬件的新热管理基线,促使整个行业加速向液冷技术转型,尤其是基于冷板与芯片直接接触散热的方案。通过平台级的设计创新以及热设计标准的制定,NVIDIA 不仅推动了 GPU 散热技术的技术路线,也带动了整个生态系统的采纳与发展。
从通用风冷到定制散热的技术演进
早期的GPU主要采用风冷系统:铝制散热片、铜热管、单风扇或双风扇结构,已足以应对游戏和轻度计算任务。然而,随着GPU在深度学习、数据分析、实时推理等高强度场景中的广泛使用,其功耗从200W以下迅速攀升至1000W甚至更高。风冷方案也随之升级到更大的散热器、更密的鳍片、更高功率的风扇层出不穷。然而在面对持续高负载和高密度部署时,风冷在噪音、热效率和稳定性上的局限逐渐暴露。
与此同时,液冷从发烧友市场扩展至主流和企业级应用。AIO(一体式)水冷系统以更高的热效率和更低的噪音优势受到欢迎,尤其适用于高端桌面和紧凑型工作站。而在GPU数据中心,冷板液冷逐渐成为主流:通过直接贴合GPU的金属冷板导热,再由冷却液带走热量,显著提升单位空间内的热管理能力。甚至有些系统将整机浸没在绝缘液体中,以获得极致的散热效率与机械简化。
冷却原理:风冷 vs 液冷
理解每种冷却方式的基本原理,有助于我们
更清楚地认识它们之间的权衡取舍。
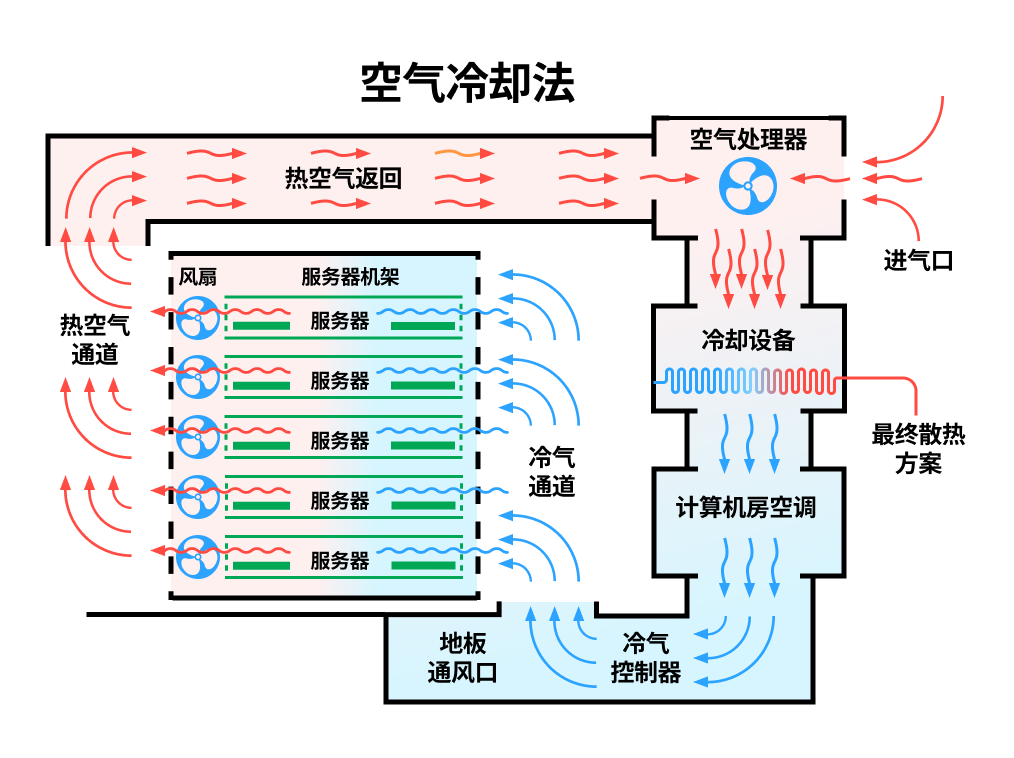
一、风冷系统:
其核心热传导路径包含三个关键环节:
- 接触传导:通过精密加工的金属底座(通常为铜或铝)与GPU芯片直接接触,利用金属的高导热性实现初始热传递
- 热管运输:内置真空热管中的工质通过相变过程(液体→蒸汽)将热量快速传递至散热鳍片阵列
- 强制对流:轴向/离心风扇推动空气流经鳍片实现最终散热
风冷系统的效率受多重因素制约。气流动力学设计直接影响散热性能,包括风道阻抗优化、湍流控制以及避免气流短路。环境空气的干球温度与密度也会显著影响散热能力,例如高温或低气压环境会降低空气的冷却效率。此外,机箱内部可能形成局部热岛效应,导致热量堆积,因此合理的风道布局至关重要。散热器材料的导热系数同样关键,例如纯铜虽然导热性能优异,但重量和成本较高,而铝合金则在轻量化和成本之间取得平衡。
以下展示风冷系统架构图:
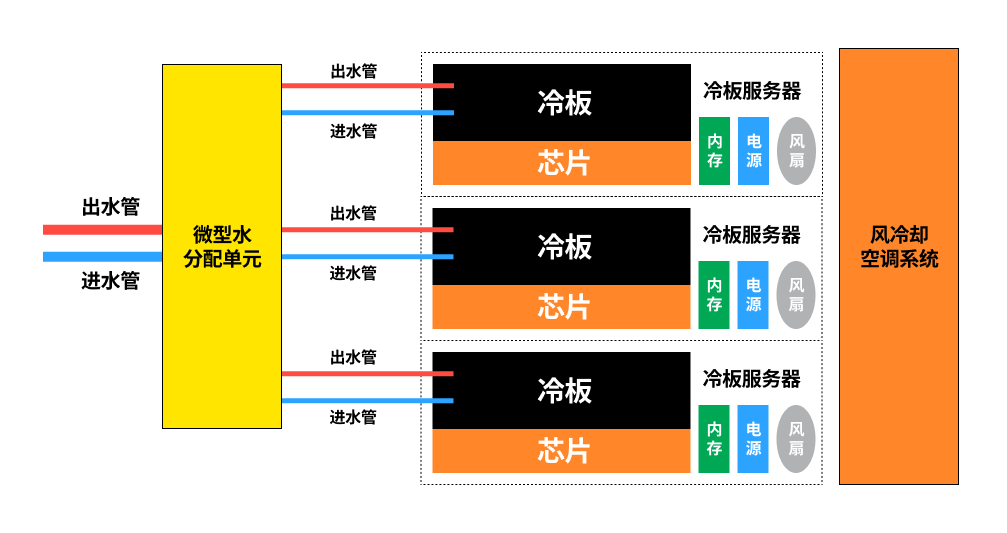
二、液冷系统:
采用两阶段热转移架构:
- 初级换热:微通道冷板通过直接接触(或液态金属界面材料)捕获GPU热量,冷却液(常见为PG25也就是25% 丙二醇加75% 水(通常为去离子水或软水)的混合液体)在泵驱下形成湍流,利用其的超高比热容吸收热量。
- 次级散热:高温冷却液流经低流阻散热排时,通过:
- 空气-液体对流换热(风冷排)
- 或相变换热(沉浸式系统)
液冷的性能优势主要源于冷却液的物理特性,其体积热容远大于空气,使得单位体积的冷却介质能携带更多热量。此外,液冷系统可突破环境温度的限制,例如采用制冷剂时甚至可实现低于环境温度的冷却效果。尽管液冷系统面临如粘度导致的能耗增加、气蚀、泄漏和维护复杂等工程挑战,但在功耗持续上升的趋势下,它正逐步成为高功率计算设备的主流散热方案,例如高性能计算(HPC)和AI加速卡。
以下展示了冷板液冷的工作原理:
在了解风冷与液冷的基本工作机制后,可以更清晰地比较它们在关键运行维度上的表现与效果。这些差异将直接影响AI基础设施中的系统设计选择。
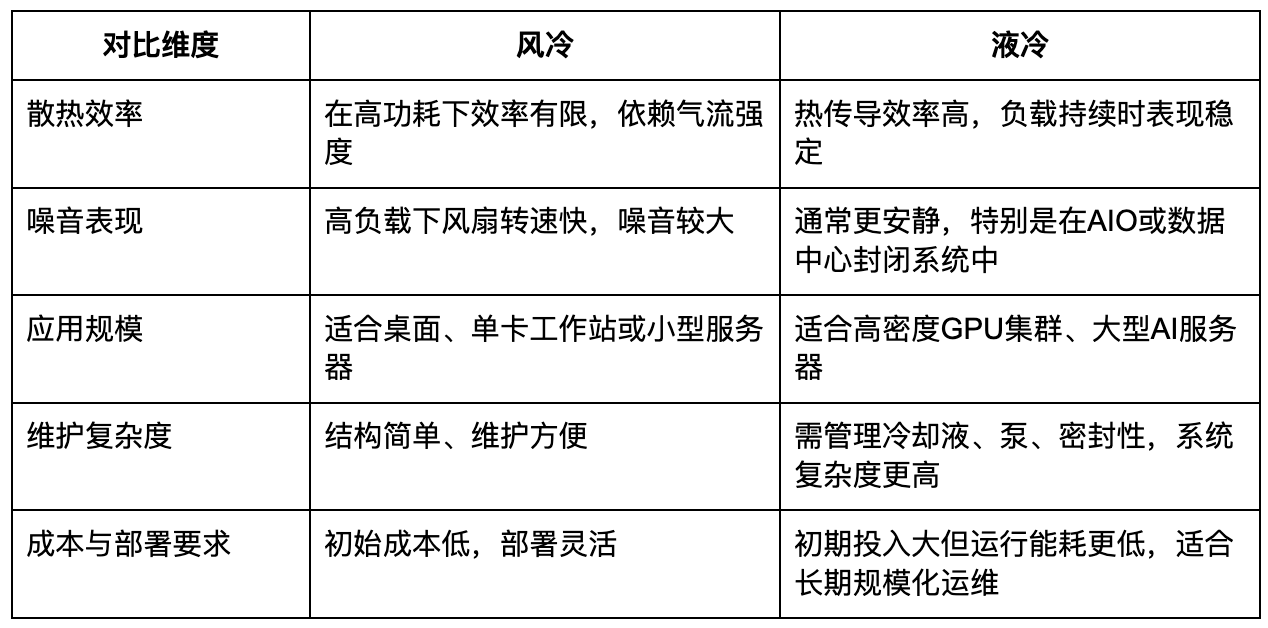
核心区别在于:风冷依赖气流将热量排出机箱,而液冷则通过液体传导将热能高效带走。后者由于液体热容与导热系数更优,具备天然的散热优势。
散热为何对AI基础设施至关重要?
在 AI 大模型的训练与推理过程中,GPU 常常需要长时间满负荷运行,产生的热量远超传统计算任务。若冷却系统无法及时有效地带走热量,不仅会导致 GPU 自动降频、响应延迟,还可能引发硬件故障和系统不稳定。散热能力已从“配套工程”演变为决定算力可用性的核心因素之一。
高效散热不仅是温度管理,更是释放算力潜力的关键。优质的冷却系统能够带来:
- 更高的GPU利用率与吞吐能力
- 更高的机柜部署密度,提升单位面积算力
- 更低的硬件故障率与运维频率
- 更低的电能使用效率,推动绿色算力中心建设
正因如此,冷板液冷已成为超大规模数据中心与主流云服务商在 AI 集群部署中的标准选择。相较风冷,它具备更高的散热效率与系统集成灵活性,为构建高密度、低能耗的 AI 基础设施奠定基础。
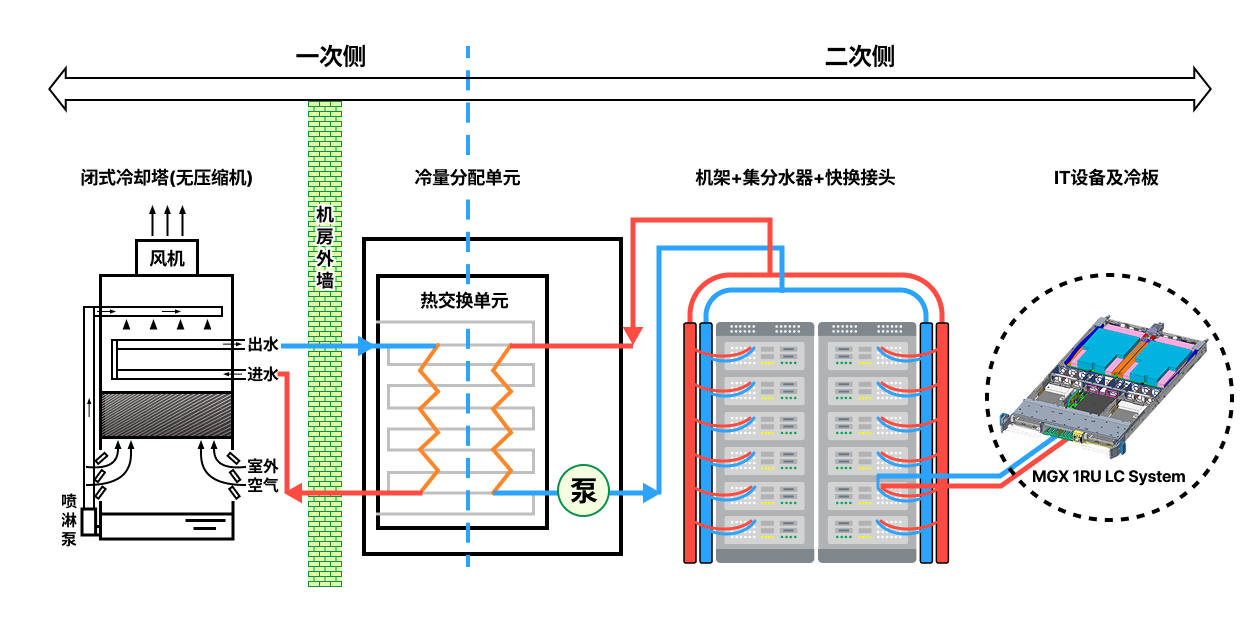
案例分析:Bitdeer AI 数据中心的 GB200 NVL72 冷却架构
在 Bitdeer AI 的 GPU 数据中心中,部署了 NVIDIA 的 GB200 NVL72 系统,这是当前计算密度最高的 GPU之一,单柜可集成多达 72 个Blackwell GPU以及36个Grace CPU。而每个GPU在峰值负载下功耗超过1000瓦,传统风冷系统已无法满足其散热需求。
为支撑如此高热密度的运行需求,单柜NVL72采用了 80% 冷板液冷 + 20% 风冷 的混合冷却架构:
- 液冷系统:GPU 核心采用单相冷板液冷方案,每颗 GPU 配备高效冷板,热量通过冷却液直接传导至冷却分配单元(CDU),并通过封闭循环将热量转移至室外冷却设备。该系统由水泵、歧管、CDU 以及液冷管路组成,构成高效稳定的热交换路径。
- 风冷辅助:用于为非核心部件(如电源模块、I/O 区域)提供辅助散热,提升整体系统的散热均衡性与结构灵活性。
这一混合冷却架构实现了 GPU 集群在高密度部署下的稳定运行,有效避免因散热瓶颈带来的降频和不稳定问题。同时,在功耗控制、运维效率和可持续性方面表现出色,成为构建新一代 AI 基础设施的关键支撑。冷板液冷方案无需对服务器结构做出大规模改动,具备成熟、易部署、易维护的优势,现已成为超大规模 GPU 集群部署的主流选择。
以下展示液冷部分处理架构原理:
结语
GPU 散热的演进,是 AI 技术发展轨迹的缩影。从辅助设计走向系统级架构集成,冷却方案早已不再是可选配置,而是关乎训练效率、能耗控制与基础设施可持续性的关键要素。在大模型带动算力指数级增长的时代,冷却能力不仅决定单卡性能是否能充分释放,更决定整柜部署密度、数据中心功耗边界与运营成本结构。风冷与液冷的抉择,不再只是技术偏好,而是一项横跨架构设计、运维策略与长期 ROI 的系统性决策。
Bitdeer AI 聚焦性能与效率,积极布局液冷技术。在 NVL72 部署中,冷板液冷与风冷结合的混合架构实现了高密度、低能耗的 AI 集群。我们相信,AI 时代的算力竞争不仅关乎芯片,更是系统工程的整体较量。当 AI 正以前所未有的速度重塑企业、产业与社会结构时,冷却系统也必须同步进化。硬件越强大,热管理越关键。唯有让冷却系统与算力系统协同演进,才能支撑通向智能时代的 AI 基础设施。