具备长期记忆的状态保持型大语言模型与AI智能体

最早的聊天机器人模型就像“金鱼”:每收到一个新提示,记忆就被彻底清除;而到了 2025 年,它们终于开始表现得更像“大象”。 通过将大上下文语言模型与外部存储结合,开发者现在可以构建“有记忆状态”的智能体,能够记住用户、项目与决策,记忆持续数天,甚至贯穿整个产品生命周期。 短期记忆的限制正在逐步消失,这得益于两大趋势的融合:
- 大上下文语言模型:开源项目如 Qwen 2.5‑1M(支持 100 万 token 的上下文窗口)和 Gradient AI 的 Llama‑3 Gradient(从 25.6 万扩展到 100 万 token),让本地部署的模型也具备了“大象般”的记忆能力。
- 具备记忆感知能力的开发框架:LangChain、LlamaIndex 和 Haystack 使得将语言模型与向量数据库、知识图谱、或情节摘要循环等内存机制集成变得更加简单。
即便是闭源模型也在迅速适应:OpenAI 最新发布的 GPT‑4.1 同样具备百万 token 的上下文窗口,说明“超大上下文”正从一项稀有功能,变成新的基础能力。
为何状态化AI至关重要
传统的大语言模型如同健谈却失忆的对话者。每次交互都从头开始,除非手动传入上下文,否则无法回忆先前的对话记录。这种无状态(stateless)架构适用于处理简单的查询,但在需要上下文连续性的场景中则显得不足,例如:能够学习用户偏好的虚拟助手、记住历史问题的客服代表,或追踪趋势变化的 AI 分析工具。
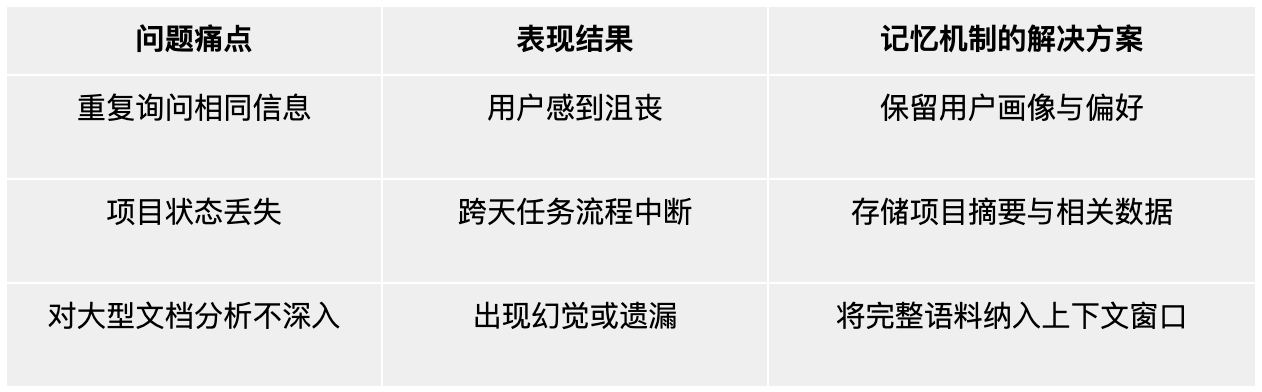
有状态保持形的大语言模型(LLMs)与 AI 智能体通过引入长期记忆机制,解决了上述问题,使其具备以下能力:
- 大规模个性化:记住用户偏好、历史记录与上下文,提供定制化的响应。
- 跨时间推理:基于过往交互积累信息,进行更有依据的决策与预测。
- 自动化复杂流程:在任务之间保持连续性,支持项目管理、供应链优化等多步骤工作。
构建有记忆状态的 AI 并非易事。这一过程需要强大的系统架构来管理内存、保障可扩展性,并避免性能瓶颈。以下是实现方式:
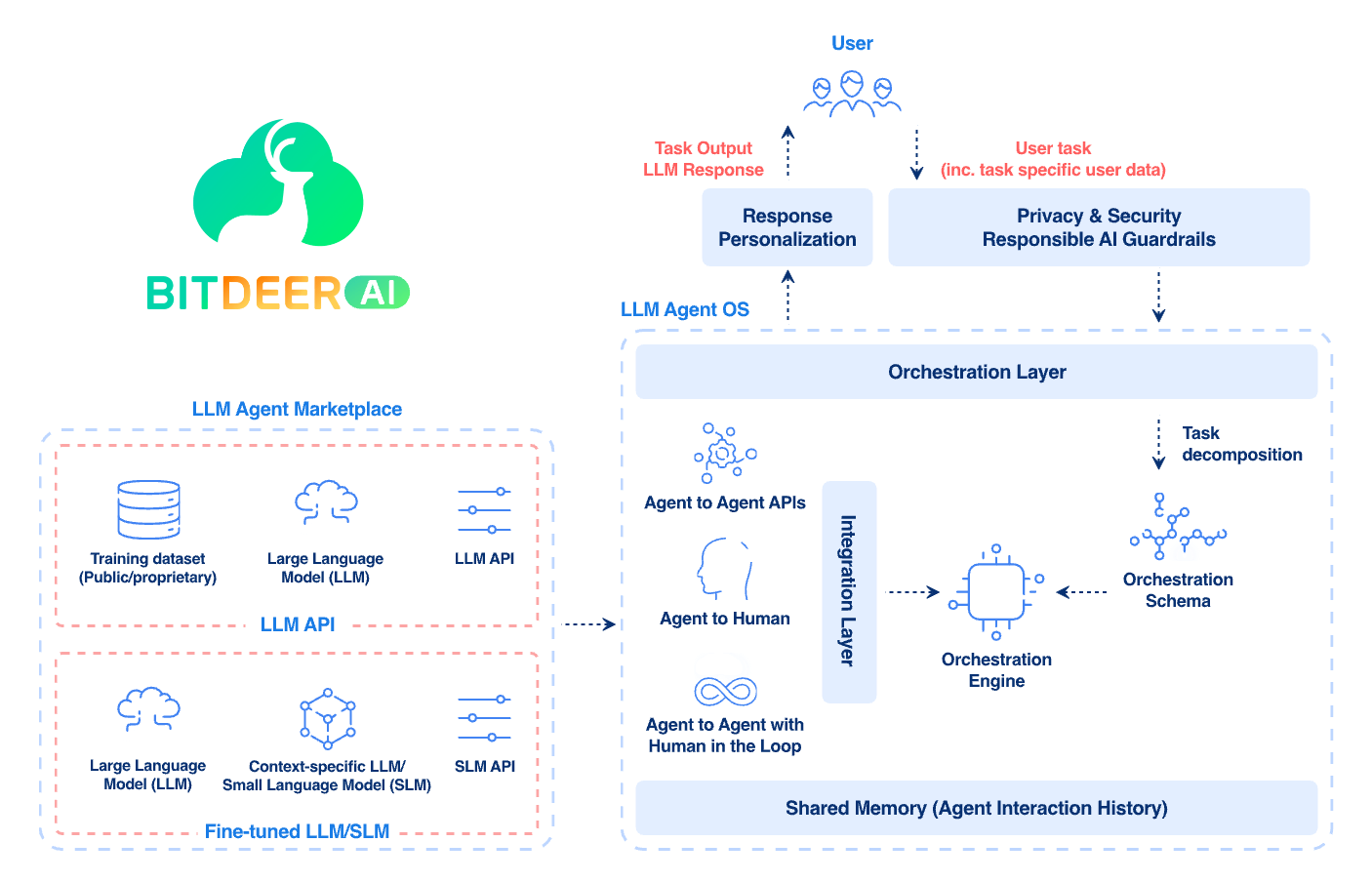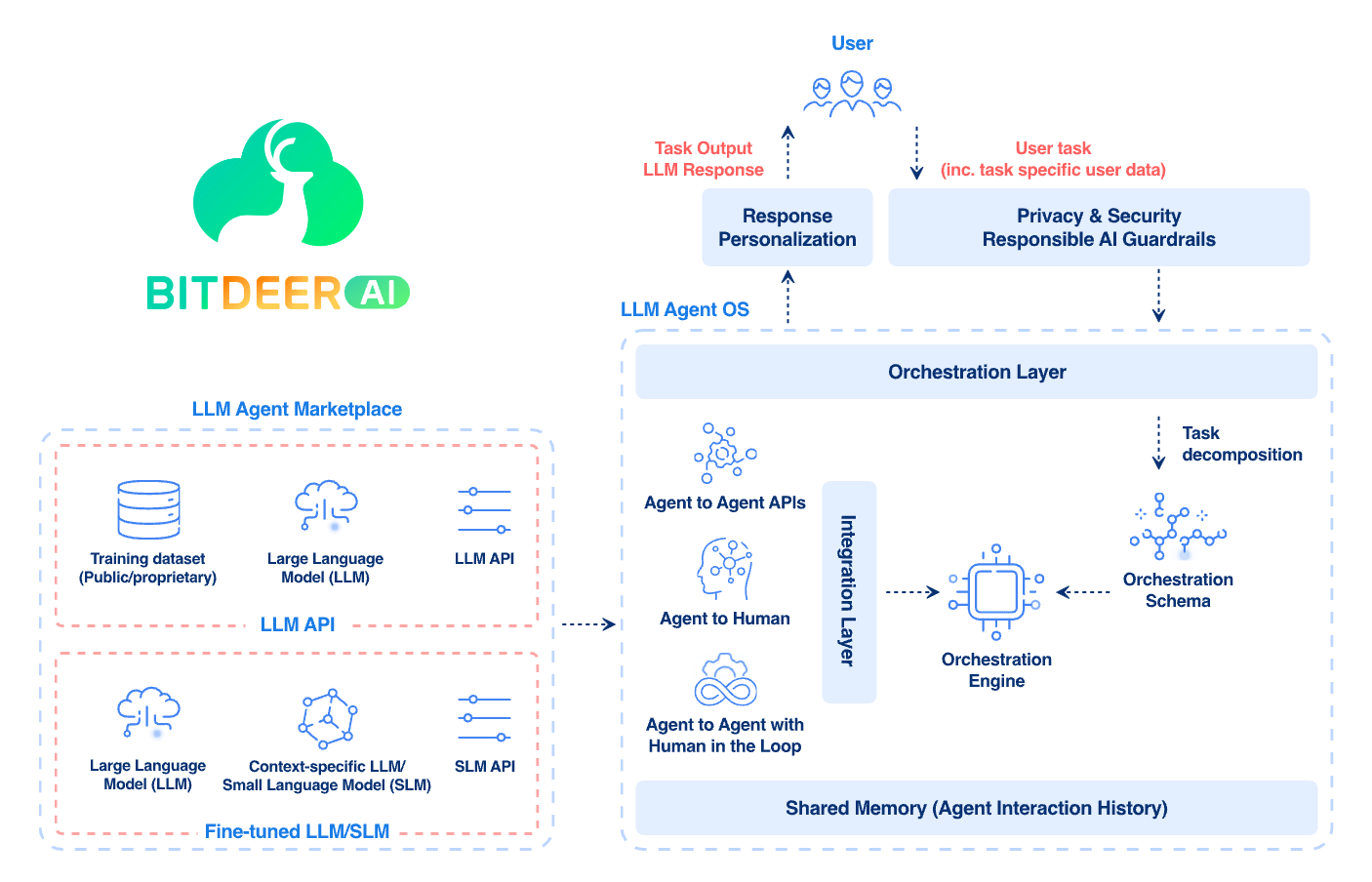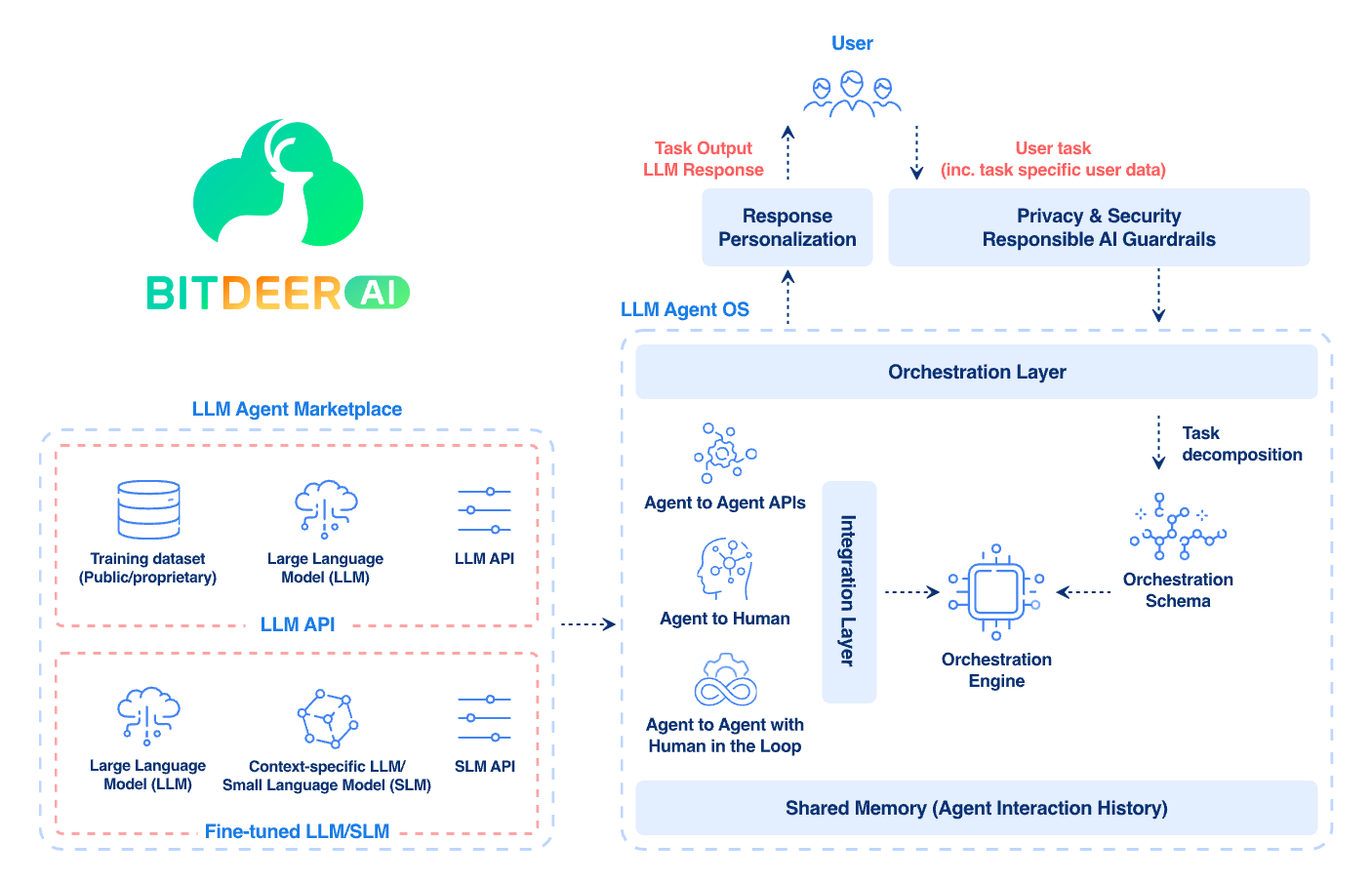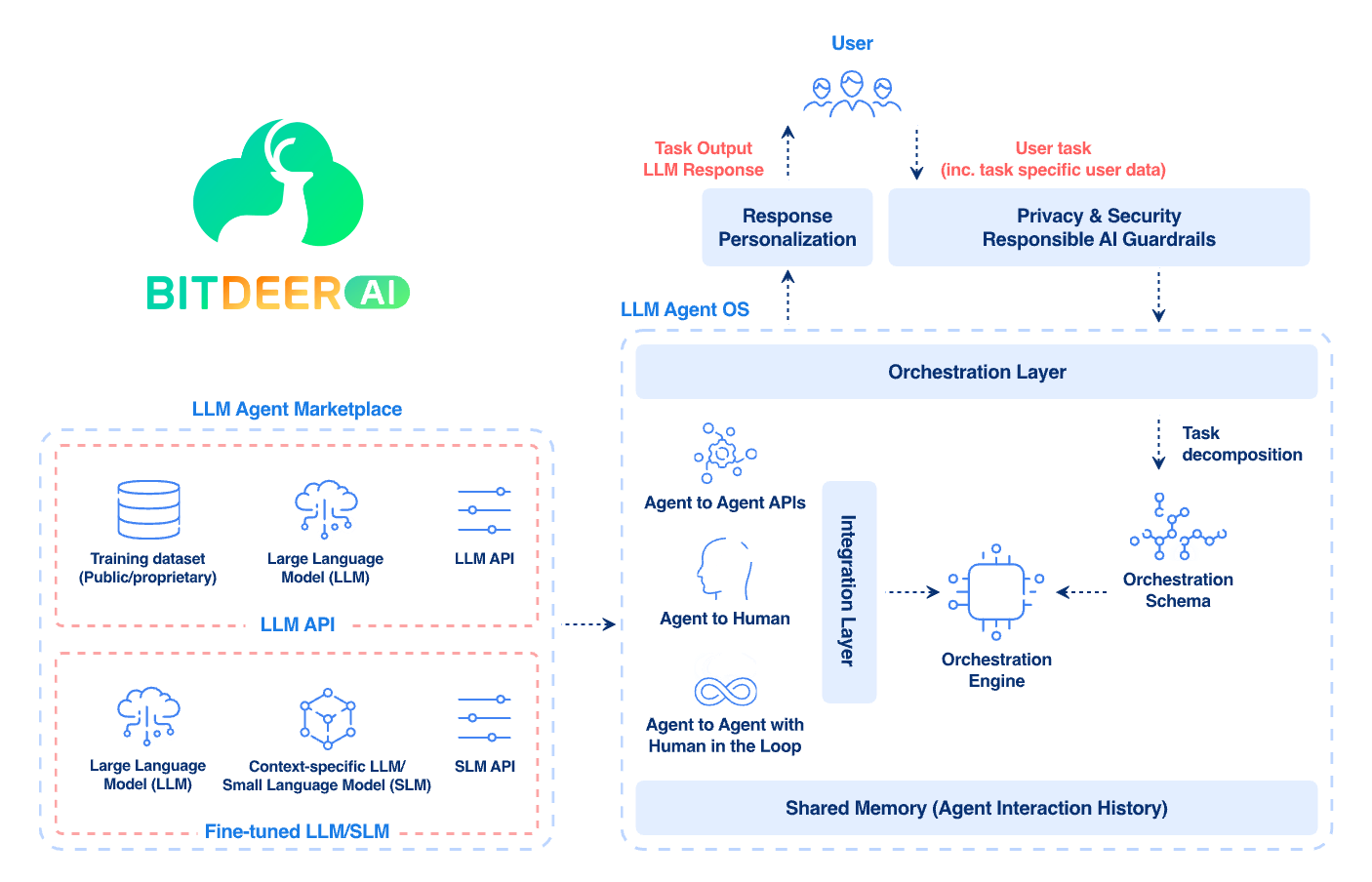
可记忆大模型与 AI 智能体的架构
有记忆状态的 AI 系统由一整套组件构成,旨在高效地捕捉、存储并利用记忆。其核心组成包括:
1. 输入处理与上下文窗口
构建的起点是大语言模型(LLM)的上下文窗口,用于处理即时输入和短期记忆。现代模型如 Llama 3 或 Mistral 已能够处理数万个 token,但仅依赖上下文窗口仍无法实现长期记忆,因为其记忆是易失的,且计算成本较高。
建议:使用动态上下文裁剪(dynamic context pruning),在传入 LLM 之前筛选出相关信息,以减少 token 冗余。
2. 记忆层
这是有记忆状态 AI 的核心部分。记忆层以结构化方式存储交互历史、用户画像或特定领域的知识。常见方法包括:
- 向量数据库:如 Pinecone 或 Weaviate 等工具,用于存储过往交互的向量表示,支持快速的语义检索。例如,客户支持代理可以检索用户的历史投诉记录以辅助生成回应。
- 键值存储:Redis 或 DynamoDB 适用于处理用户偏好、会话状态等轻量级结构化数据。
- 图数据库:Neo4j 或 ArangoDB 可建模复杂关系,适用于需要跟踪实体间关联(如供应链节点)的智能体。
设计模式:将向量数据库与键值存储结合使用构建混合记忆架构。向量用于语义上下文检索,键值用于存储如时间戳、用户 ID 等元数据。
3. 状态管理与调度
调度层负责管理记忆的调用、更新以及与大语言模型(LLM)的整合。这一层是 AI 智能体发挥作用的核心所在,它们充当控制器,决定何时读取记忆、调用工具,或在必要时转交人工处理。LangChain、Haystack 等框架提供调度逻辑支持,而基于容器的微服务架构(例如通过 Kubernetes)则保障系统的可扩展性。
设计模式:结合 LLM 调度框架构建反馈循环,通过记忆更新不断优化模型的相关性。
4. 输出与交互层
这一层负责生成最终响应或执行操作,通常通过 API 与外部系统(如 CRM、ERP)集成。对于 AI 智能体而言,这可能包括执行具体任务,如安排会议或生成报告。
设计模式:使用输出模板确保响应一致性的同时,允许根据记忆实现个性化内容输出。
开源工具构建状态保持型AI
开源生态中提供了丰富的工具来开发具备状态保持能力的大语言模型和AI智能体。以下是精选技术栈:
- 大语言模型(LLMs)
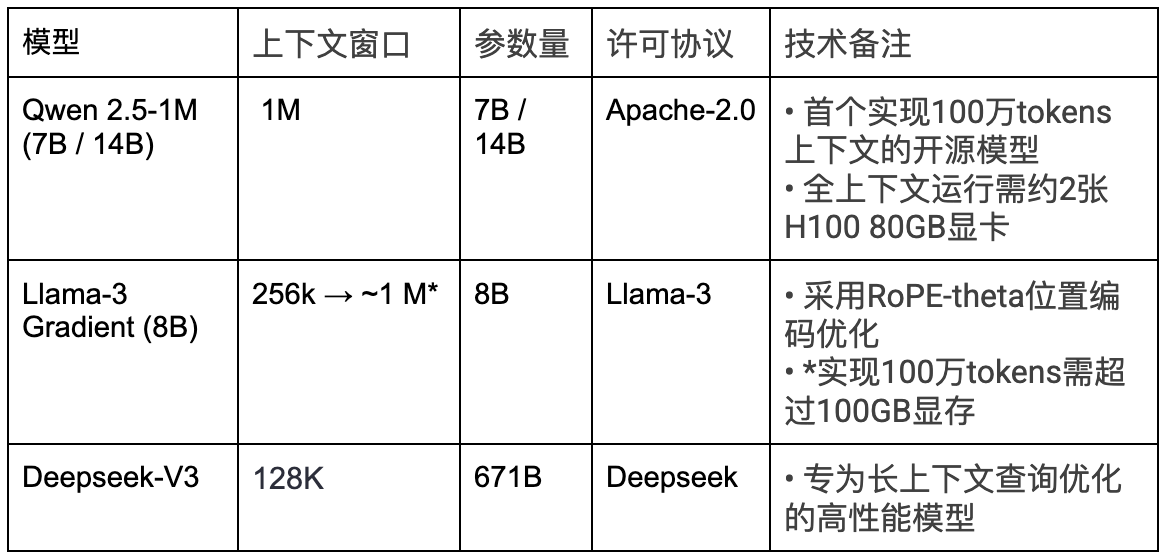
建议: 若无需完整的百万级上下文窗口,128k–256k的模型在单台H100 80GB节点上即可流畅运行。
- 存储方案选型:
- 向量数据库:Weaviate(可扩展,内置嵌入支持)或Faiss(轻量级,适用于研究)。
- 键值存储:Redis(内存中,低延迟)或RocksDB(持久化,高吞吐量)。
- 图数据库:Neo4j(企业级)或Dgraph(云原生)。
- 调度:LangChain(代理工作流,工具集成)或LlamaIndex(数据连接器,内存管理)。
- API与集成:FastAPI用于构建RESTful端点,或Apache Kafka用于实时数据流。
- 监控:Prometheus和Grafana用于跟踪内存使用、延迟和模型性能。
提示:从LangChain开始进行快速原型开发,然后过渡到使用FastAPI和Kubernetes进行定制调度,以实现生产级别的可扩展性。
最佳实践与常见误区
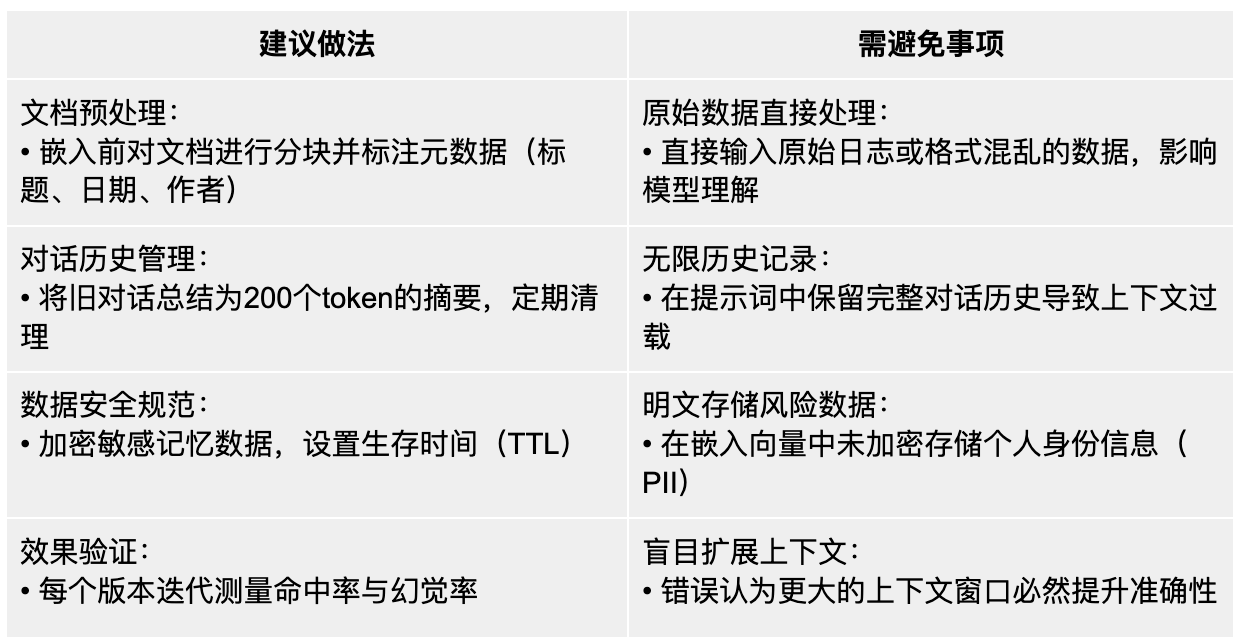
实战案例:构建具备长期记忆的编程助手
场景需求:开发一款内部开发辅助工具,需持续记忆三个月冲刺周期内的系统架构决策记录
未来发展方向
具备状态保持能力的大语言模型(LLMs)与AI智能体代表了下一代技术前沿,它们将记忆功能与智能计算相融合,打造出具有类人持续认知能力的系统。这类AI不仅能回答问题,更能建立长期交互关系、持续解决问题,并伴随企业共同进化。在这个以上下文认知为核心竞争力的时代,状态化AI将成为您最具战略价值的核心技术资产。