并行思考:Multiverse 如何重构并行推理范式

大语言模型正在成为现代 AI 系统的核心驱动力,但它们的生成方式至今依然深受主流的“自回归”机制的限制。这种逐词输出的线性逻辑虽然简单有效,却天然不适合解决结构复杂、逻辑多元的推理任务。模型的参数越来越大,对算力的要求也极具增加。是否能有什么方法提升模型的效率来应对这些问题?
最近,由卡耐基梅隆大学(CMU)Infini-Al-Lab 和NVIDIA研究者联合完成的最新工作发表了《Multiverse: Your Language Models Secretly Decide How to Parallelize and Merge Generation》文章,Bitdeer AI 提供了训练与推理阶段的 GPU 算力支持。其团队的这项研究提出了一个核心观点:并行逻辑并不缺席于语言模型,只是以往的监督微调技术并非有效利用其逻辑。他们提出了Multiverse, 一个能够实现原生并行生成的新型生成模型,其最终成果Multiverse-32B 在真实推理任务中性能媲美 AR-LLMs,并凭借并行生成在相同上下文下展现更优扩展性。其单 token 生成耗时可减少达 2 倍(视并行度而定)。Multiverse 是一个大胆的尝试, 它让模型自己决定何时并行、如何并行、怎样合并,打破了长期以来的生成瓶颈。
如何提升模型效率
当前主流大模型(如 GPT、Gemini、Claude 等)大多基于自回归(autoregressive)架构,即生成一个 token 后,才能继续生成下一个。这种机制有两个直接限制:
- 无法并行生成,导致推理效率随长度线性下降;
- 难以表达复杂结构推理,所有推理链只能压缩成单一路径输出。
过去虽然有诸如 Tree of Thoughts、Best-of-N、MCTS 等尝试让模型从多个路径探索再合并答案,但这些方式通常依赖外部搜索器或工具,既无法保持内部状态的一致性,也会造成推理上下文的丢失与延迟。
Multiverse 的洞察在于:即便没有并行生成能力,现有大模型在长文本输出中经常“自然生成出可并行的逻辑结构”。例如分析问题的多个子部分、并列的案例推理、递归结构展开等。这些潜在的“并行性”,一直被 AR 模型忽略或线性压缩,浪费了本可以并行处理的大量推理机会。
Multiverse:让模型自己决定并行方式
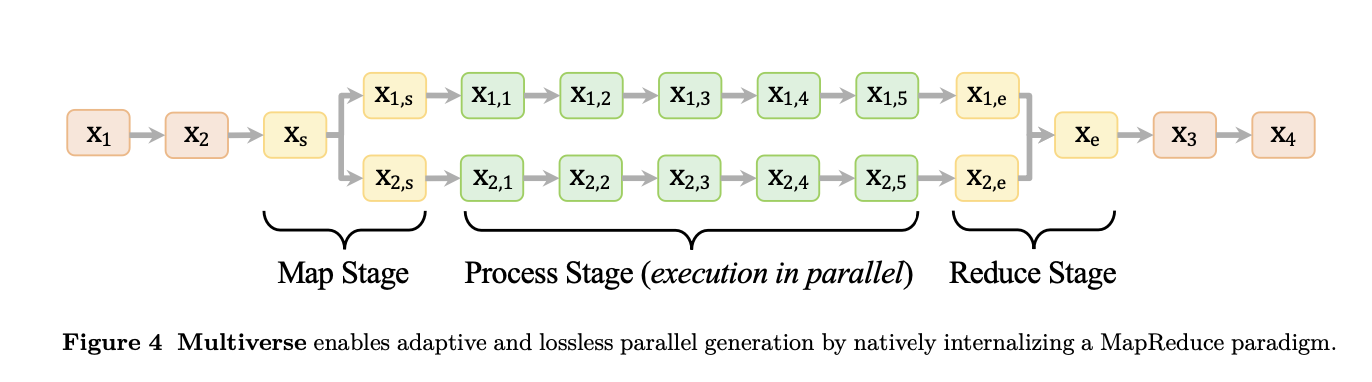
Multiverse 并非一个增强器或搜索器,而是一个从模型结构、训练数据、推理引擎三方面共同设计的全新生成体系。它借鉴了 MapReduce 的计算思想,将语言生成流程解构为三个原生阶段:
- Map 阶段:模型自动拆解复杂任务,生成结构性目标(如“考虑三种情况”、“并列分析两个方向”);
- Process 阶段:每个子任务通过独立路径并行展开推理,各自拥有上下文前缀和专属 token 流;
- Reduce 阶段:所有分支推理结果在模型内部无损合并,回归统一语义流。
与传统 AR 模型只会顺着一条路走到底不同,Multiverse 像一个拥有内部程序控制逻辑的“生成智能体”,它能自动识别哪些内容可以并行,何时切换生成模式,并完整保留上下文状态。
这种结构的关键创新在于它是完全内生的。所有并行调度、路径合并、上下文处理都是由模型自身生成与触发的,而不是外部模块介入。这保证了模型的连续性、一致性与表达完整性。
从理念到真实应用
Multiverse 的提出不仅仅是一个新模型,而是一个“从数据到部署”的系统工程。为了将 Multiverse 部署到实际场景中,该工作提供了一套完整的套件,其中包括 Multiverse Curator(数据生成器)、Multiverse Attention(核心算法)和 Multiverse Engine(优化系统)。:
- 数据层面:研究团队提出了自动化数据生成工具“Multiverse Curator”,通过调用现有大模型,将原始顺序推理链解析成结构树,识别可并行的节点,转换为包含 <Parallel>、<Goal>、<Path> 等控制标签的 MapReduce 格式。这一过程避免了人工标注,为结构化推理构建了 Multiverse-1K 高质量训练集。
- 模型层面:核心创新之一是“Multiverse Attention”,一种对传统注意力机制的轻量修改。它允许模型在 Process 阶段并行计算多个子路径,同时保持每条路径独立,最终在 Reduce 阶段整合上下文。这种设计兼容已有模型结构,使得原有自回归模型只需微调即可转化为 Multiverse 架构。
- 系统层面:Multiverse Engine 构建在 SGLang 推理框架之上,支持结构化标签识别与动态推理路径切换。比如,当模型生成 <Parallel> 时,系统立即分配多个路径线程进行并行执行,并在 <Conclusion> 标签出现后自动回归为统一序列生成。整个执行过程无需人工干预,运行高效而灵活。
这一机制使得 Multiverse 模型在训练、推理两端都具备原生支持并行生成的能力。
性能表现不止于速度提升
Multiverse 的最终成果是一个32B规模的模型 Multiverse-32B,它基于 Qwen2.5-32B-Instruct 进行微调,仅用1000条结构化样本,在 8 张 B200 GPU 上完成了 3 小时内的全流程训练。
实验结果表明:
- 推理精度提升显著:在 AIME24、AIME25、MATH500、GPQA 等高难度推理任务上,Multiverse-32B 的表现与最佳 AR 基线相当甚至更优;
- 生成并行度提升:该模型在 AIME24 任务上达到了约 1.18 的并行生成比率,这意味着相比自回归基线模型,它在单位生成长度内能够生成更多有效的 token;
- 生成效率翻倍:在相同上下文 budget 下,Multiverse 相比传统模型提升了最多 2 倍的推理速度,同时保持甚至提升了准确率;
- 优秀扩展性:batch size 扩张至 128 时仍保持稳定加速与内存高效复用。
这不仅证明了“并行推理可行”,更说明它在不牺牲质量的前提下能够提升效率、降低延迟,为下一代实时推理系统铺平道路。
结语
Multiverse通过大规模并行生成显著提升GPU利用率,尤其在小批量和长上下文推理场景中优势明显,能有效降低延迟和能耗。此外,它还能以接近恒定的总延迟实现难以并行任务的规模经济,即使任务复杂度增加也能缩短单位耗时。
未来的 AI 不应只是“生成器”,而应该具备结构控制、路径调度和任务规划能力。Multiverse 展示了一种可能:语言模型可以不仅理解语言,更可以编排自己的思维流程。我们相信,随着 Multiverse 的开源及更多模型的跟进,这一方向将在自动化工作流、代码生成、多步决策等任务中找到更广泛的应用场景。
算力不仅是 AI 研究的燃料,更是将算法“真正落地”的必要条件。我们很自豪地为该研究提供了GPU 算力服务,在未来Bitdeer AI 将持续为此类通用智能模型提供算力支持,并推动生成式 AI 在性能与智能表达能力上的协同演进。