NVIDIA GB200 NVL72释放 AI 无限潜能

随着人工智能的快速发展,模型规模和计算复杂度不断提升,对底层计算硬件提出了更高要求。其相关工作负载对算力、效率和系统稳定性的依赖日益增强,只有具备先进架构与持续性能输出能力的计算平台,才能支撑这一进程。在这一领域中,NVIDIA GB200 NVL72 的面世,是重要的一个节点,备受行业的关注。GB200 NVL72是面向高性能计算与人工智能工作负载设计,依托 NVIDIA 在加速计算领域的架构积累,正在推动人工智能开发与规模化部署进入新的阶段。
什么是 NVIDIA GB200 NVL72?
NVIDIA GB200 NVL72 是一套面向大规模人工智能训练与推理工作负载的机架级人工智能系统。该系统基于 NVIDIA Blackwell 架构构建,由 36 颗 Grace Blackwell Superchip 组成,每颗 Superchip 集成一颗 NVIDIA Grace CPU 与两颗 Blackwell GPU,在一个采用液冷设计的单一机架中共包含 72 颗 GPU 和 36 颗 CPU。。
通过完整的 NVLink 与 NVLink Switch 互连,系统内所有 GPU 以高度耦合的方式协同运行,使整个平台在逻辑上表现为一个整体计算单元,而非多个彼此独立的加速器。这种架构显著降低了 GPU 之间的通信开销,并针对模型规模较大、参数交换频繁,以及需要在大规模条件下保持稳定、可预测性能的长时间训练或推理任务进行了优化。
从 H100 到 GB200 NVL72 的技术演进
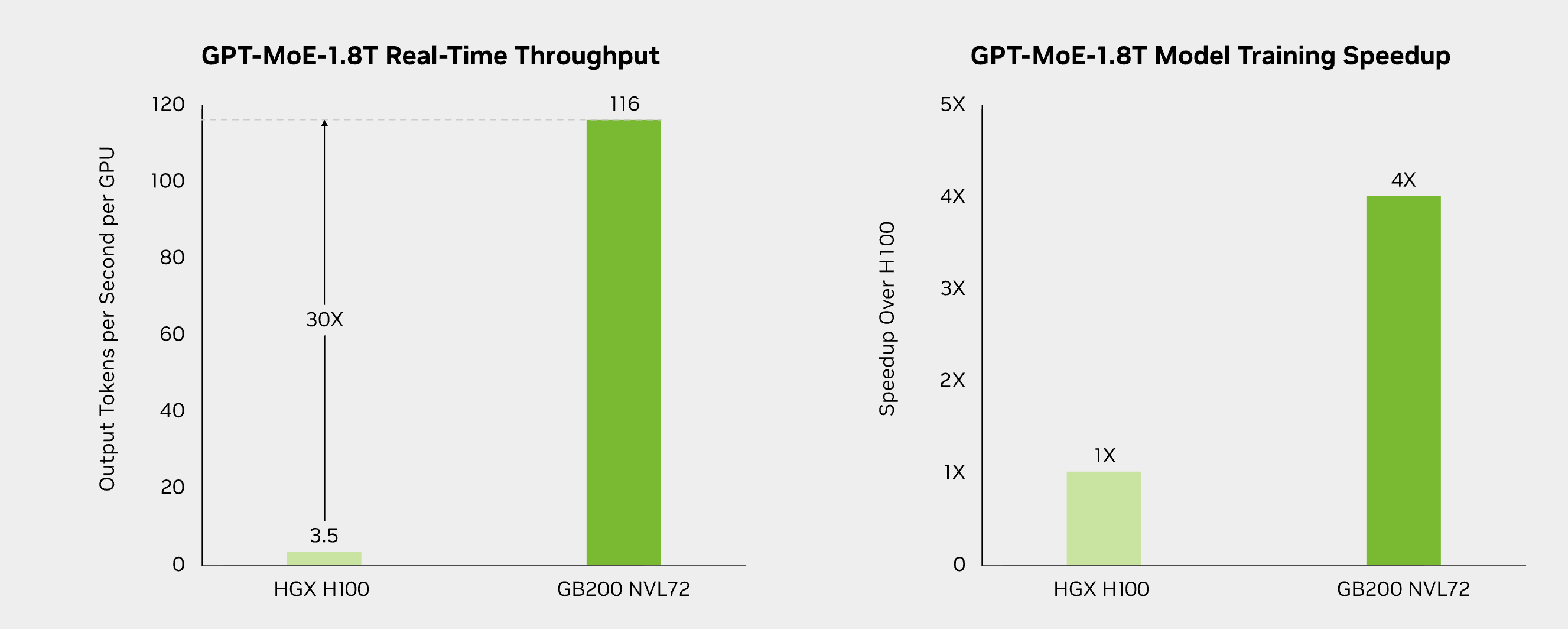
尽管 H100 在基于 Transformer 架构的人工智能计算方面实现了重要突破,GB200 NVL72 在此基础上通过系统级层面的改进进一步演进。相较于 H100,GB200 NVL72 引入了新一代 Tensor Core 以及更新的第二代 Transformer Engine,并针对新的 FP4 精度进行了优化。与 H100 所采用的 FP8 相比,该设计在计算能力和可支持的模型规模上实现了成倍提升,尤其有利于超大规模大语言模型的推理任务。这些改进直接作用于大语言模型的训练与推理场景,其中矩阵运算在整体运行时间中占据主导地位。
互连架构是另一项关键差异点。基于 H100 的集群通常依赖节点内的 NVLink 以及节点间的高速网络,在大规模部署时可能引入额外的延迟与同步开销。GB200 NVL72 则通过 NVLink Switch System 将 NVLink 域扩展至整个机架内的 72 颗 GPU,提供相比上一代高达 9 倍的总体带宽,使整个机架在逻辑上被视为一个统一的 GPU。
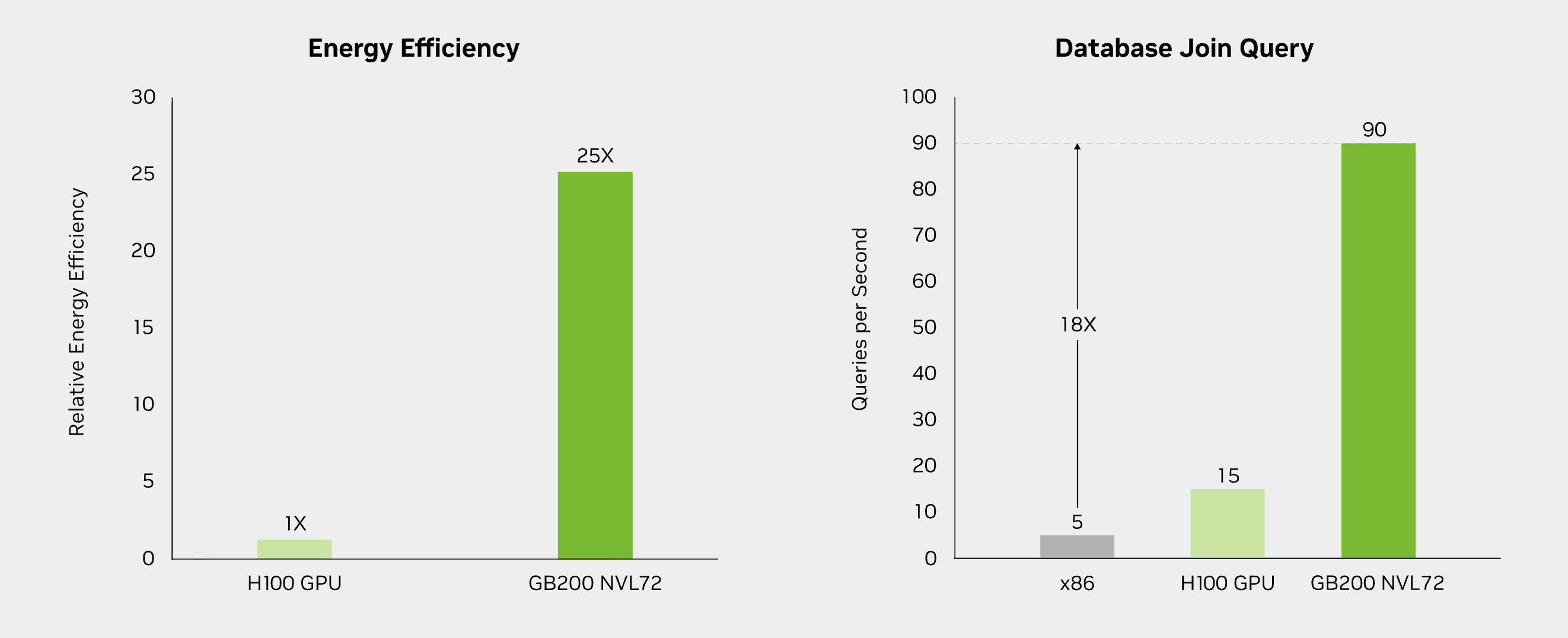
在内存访问层面,系统级优化同样带来了改进。通过加速参数共享与集合通信操作,GB200 NVL72 提升了整体资源利用效率,尤其适用于模型规模超出单个 GPU 显存容量的场景。最后,GB200 NVL72 是一套以液冷为原生设计的系统。这一转变对于应对单机架超过 120 千瓦的功率密度至关重要,使系统能够在持续运行条件下保持峰值性能,而这是传统风冷方案在物理条件上难以实现的。
这些架构层面的变化不仅体现在设计理念上,也直接反映在真实人工智能工作负载的性能表现中。后续的基准测试将从大语言模型训练效率、推理吞吐量、能效表现以及数据处理性能等方面,对 GB200 NVL72 与基于 H100 的系统进行对比分析。
来源:NVIDIA 官方网站
业务应用场景:GB200 NVL72 的适用领域
NVIDIA GB200 NVL72 面向对计算吞吐、扩展效率以及持续性能有较高要求的人工智能工作负载而设计。其机架级架构适用于多种企业级应用场景,在这些场景中,训练速度、推理效率以及运行成本会直接影响业务结果,覆盖医疗健康、金融服务以及以人工智能为核心的技术型企业等多个行业。
- 大规模人工智能模型训练
GB200 NVL72 适合用于训练规模大、结构复杂的人工智能模型,相关应用包括自动驾驶、医疗健康、机器人技术以及自然语言处理等领域。凭借高性能的 Tensor Core 与更高的系统级吞吐能力,该平台能够缩短深度学习模型的训练周期,从而加快实验迭代速度,并推动模型从研究阶段更高效地进入部署阶段。
- 高性能人工智能推理
除训练场景外,GB200 NVL72 同样适用于对响应速度和稳定性要求较高的推理工作负载。视频分析、推荐系统以及实时决策支持等应用,能够受益于其在大规模条件下高效执行推理任务的能力,帮助企业提供更具响应性的人工智能服务。在医疗健康与生命科学领域,医学影像分析、基因组计算以及药物研发等工作负载通常涉及大规模数据集和长时间运行的训练任务,该平台有助于缩短训练时间并提升资源利用效率,从而支持更快的实验推进以及从研究环境向临床或生产环境的过渡。
- 面向规模化部署的能效优化
GB200 NVL72 在设计上兼顾性能与能效,适用于对功耗与运营成本较为敏感的大规模人工智能部署场景。这一特性对于持续运行工作负载的云服务提供商、企业级人工智能平台以及科研机构尤为重要,因为在规模化运行条件下,系统效率将直接影响整体拥有成本。
- 支撑下一代人工智能应用
通过支持更大规模的数据集以及日益复杂的模型结构,GB200 NVL72 为不同行业开发和部署下一代人工智能应用提供了基础能力。这类应用包括多模态人工智能系统、共享型基础模型,以及服务于多个业务部门或客户的人工智能平台。该平台使企业能够在模型复杂度不断提升的过程中,逐步扩展人工智能能力,同时保持性能表现与系统架构的一致性。
Bitdeer AI 与 NVIDIA GB200 NVL72 集群
随着 Bitdeer AI Cloud 平台不断扩展其 NVIDIA GPU 产品体系,平台正在覆盖更加多样化的人工智能计算需求。NVIDIA GB200 NVL72 的引入,使平台在支持更大规模、通信更密集的人工智能工作负载方面具备了更强的能力。同时,平台原有的 NVIDIA H100 仍然在大量训练与推理场景中发挥着稳定作用,共同构成了覆盖不同模型规模与部署需求的计算基础。
通过同时提供这两类GPU资源,Bitdeer AI Cloud 使用户能够根据模型规模、工作负载特征以及运行需求,选择更契合自身场景的 GPU 配置。